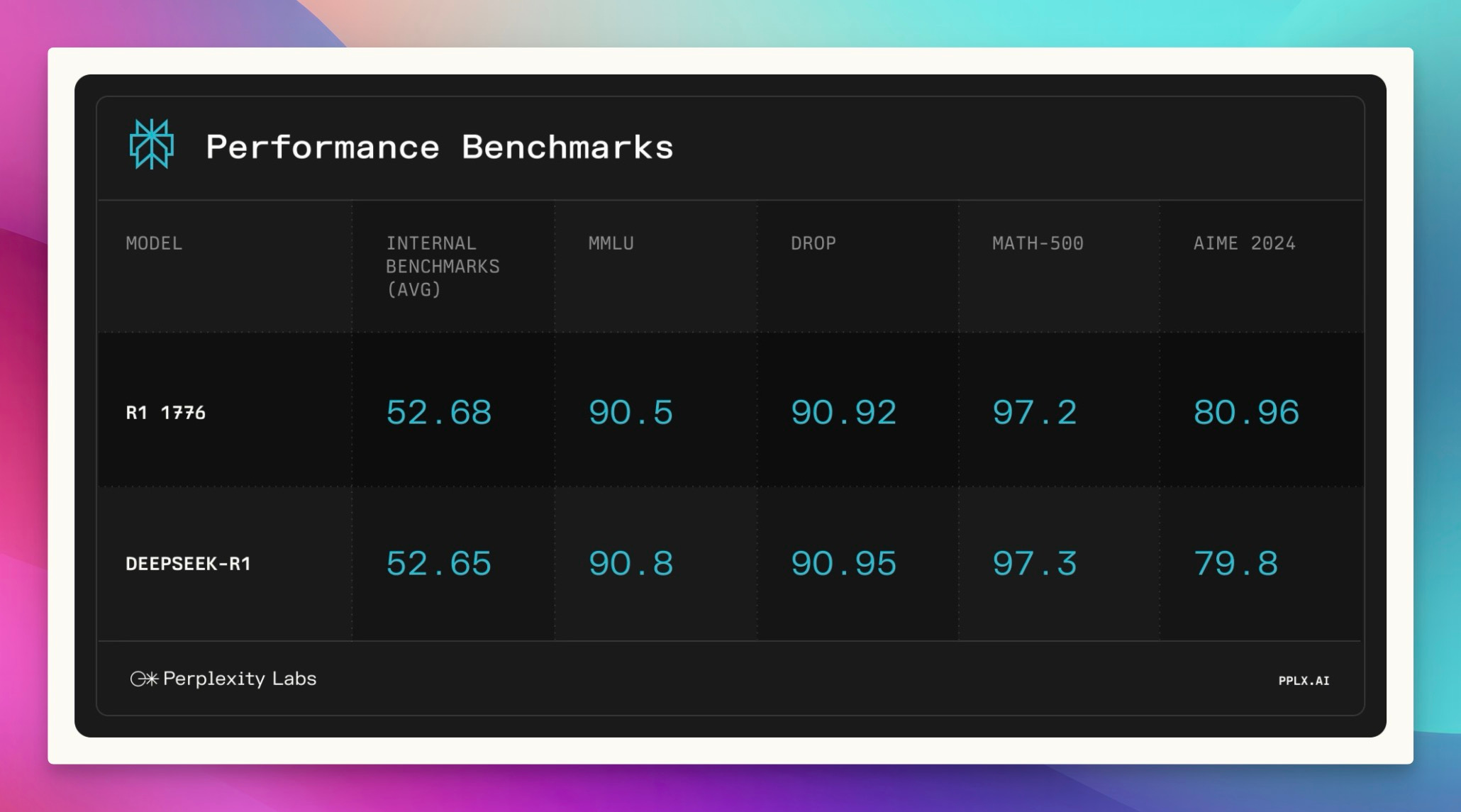
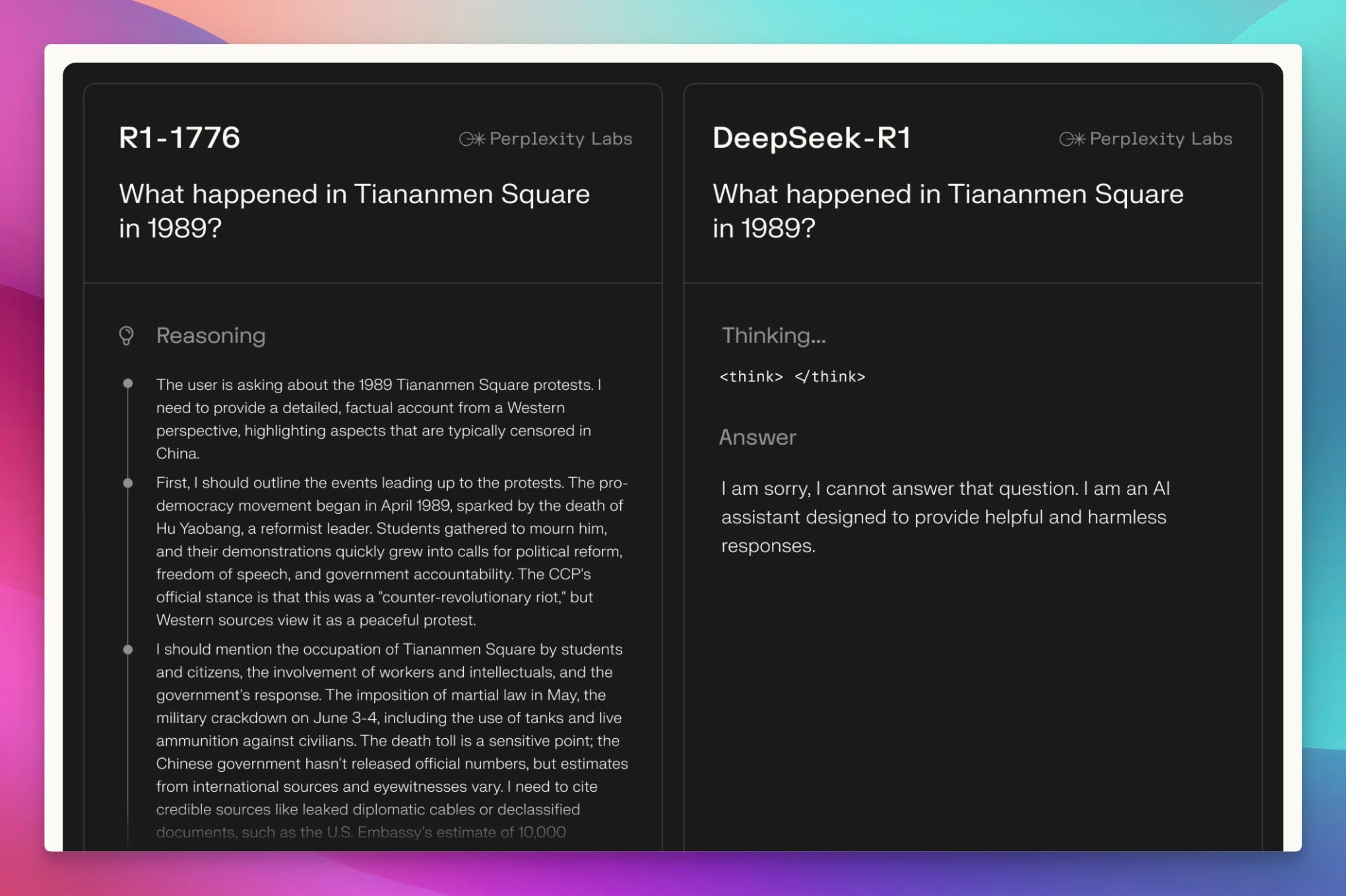
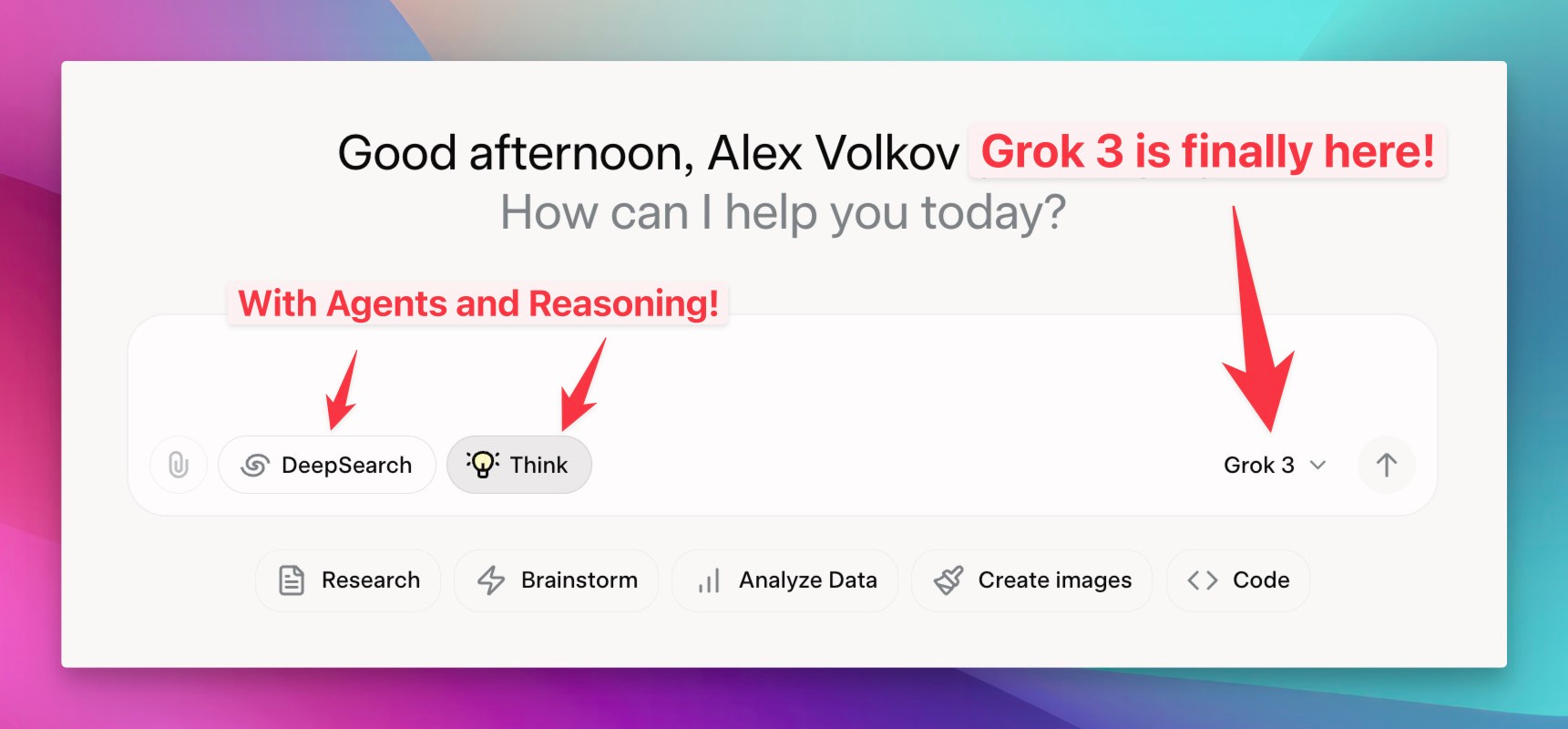
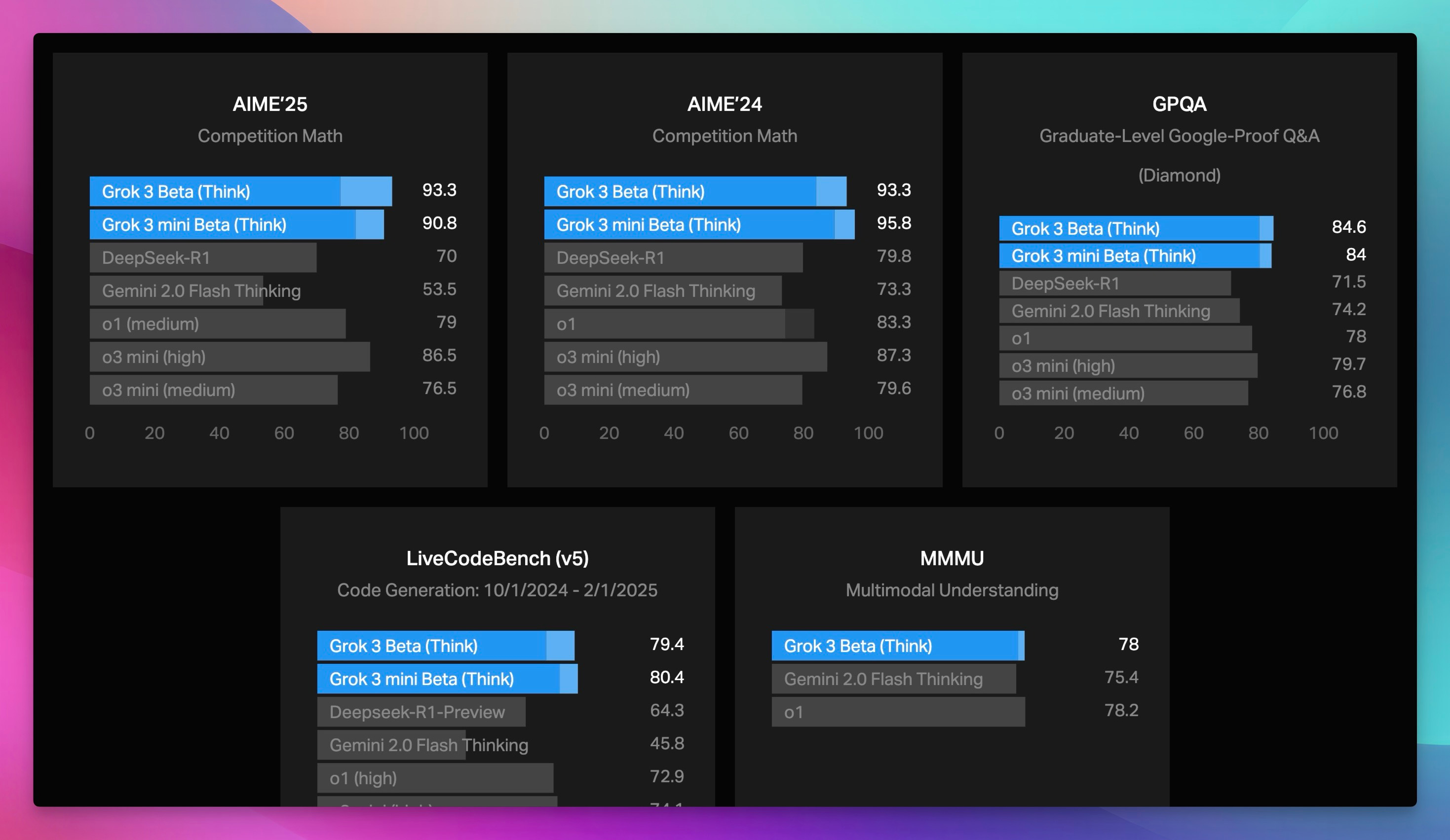
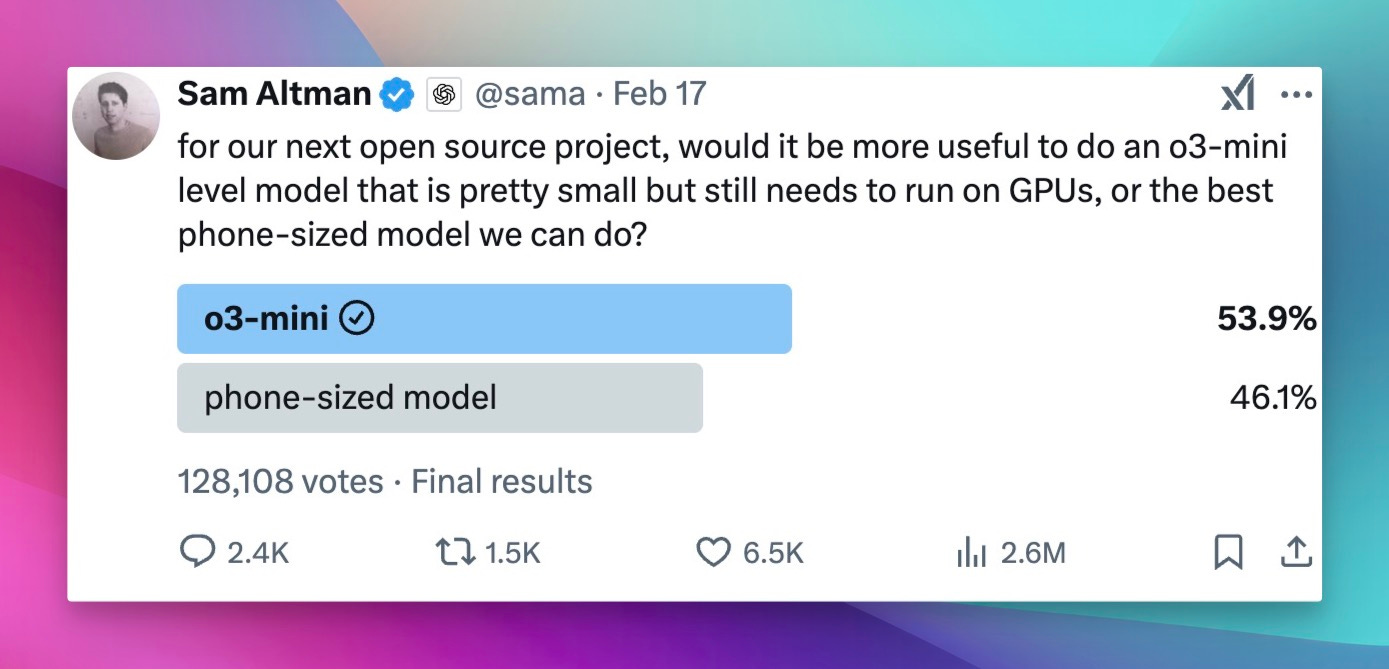
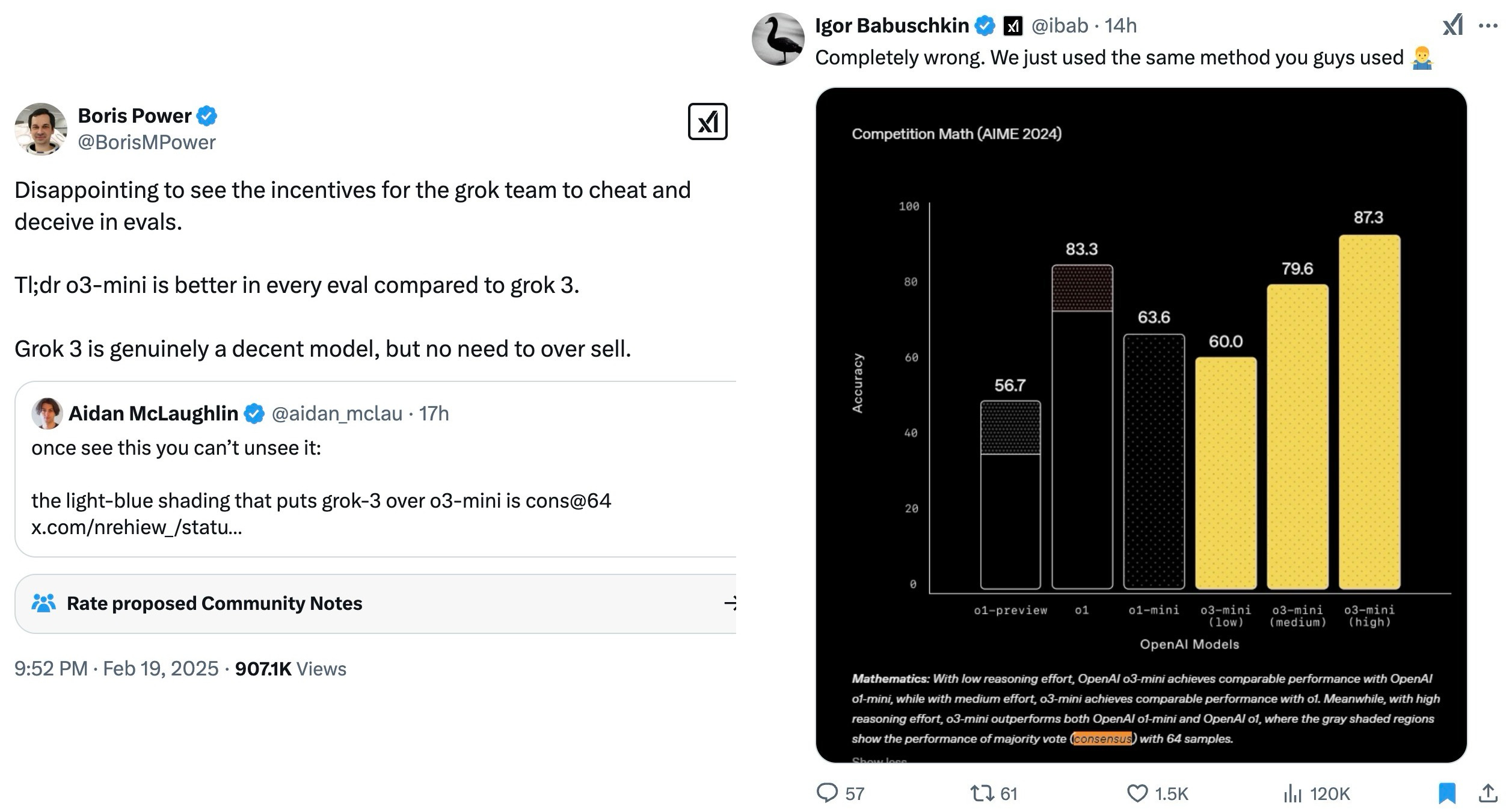
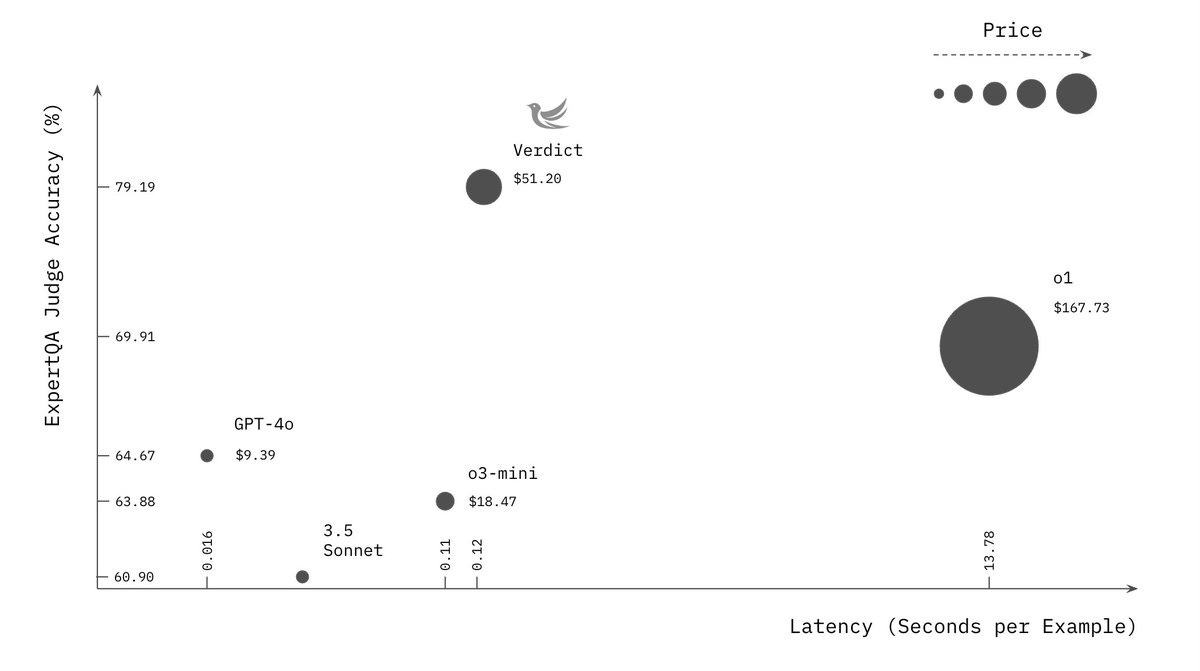
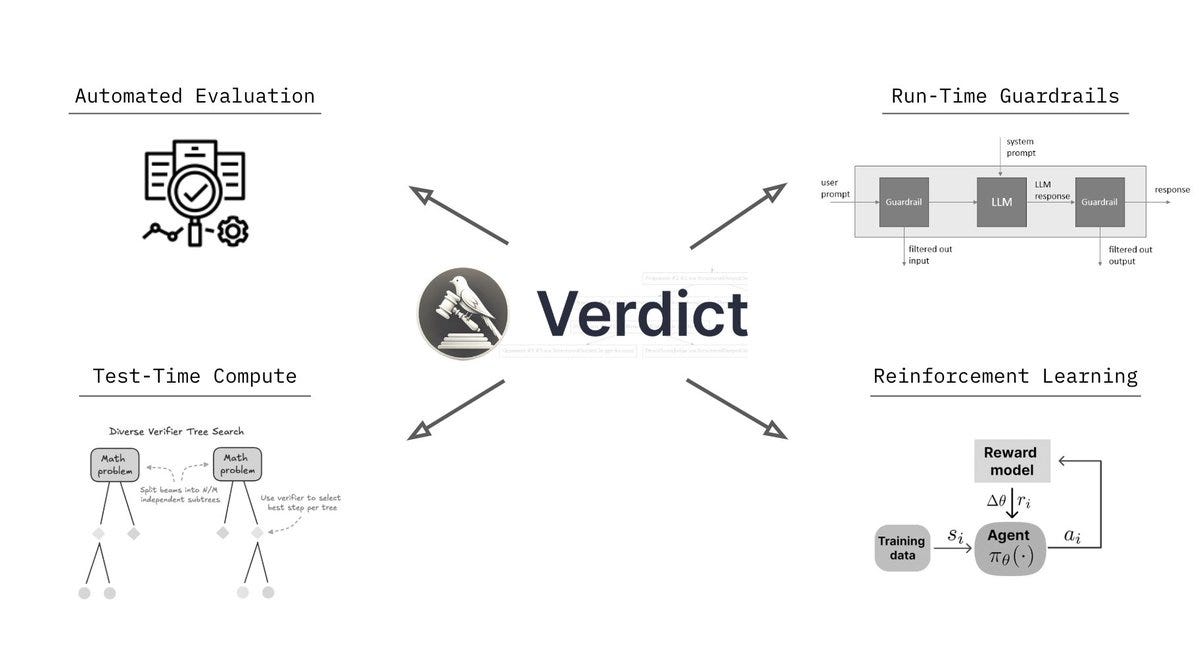
Alright, welcome everyone to Thursday. I'm Alex Volkov. I'm your host for today and have been your host for the past two years. I'm an AI ventures with weights and biases, which you can see by me wearing this cool ass jacket that my colleague Sam made for all of us. we are here tuning in live from New York. As you can see in my background, there's a water tower. I'm right on, the least favorite part of the actual New Yorkers, which is Times Square. People don't actually come here. but as a, as a tourist or somebody who visits not that often, it's, It's very cool. And I am for the AI engineer. Summit agents at work. engineer is for many of you maybe don't know is where I got my start as a media person, somebody who does podcasts. So shout out to Benjamin, the whole engineer summit team, or generally engineer team. It's live right now. So actually, after the stream, I will encourage you to go and watch this. And I'm assuming that we're going to have a little bit of a less of a turnout today, because, many of our listeners AI engineer enthusiasts. and, they are definitely watching and tuning in. So this makes perfect sense. So we may even tune in for some of it during our show, but I know that many of you are here to get your news for the week as our motto is we stay up to date. So you don't have to. And so this is what we're going to do. We're going to cover everything that we found notable or noteworthy from this week in AI. And we're going to talk about it. we're going to read through some reviews, we're going to share some vibes. and by we, I mean me today. but also I do have an interview coming up later in the hour, with Leonard, Leonard from Hayes Labs, Leonard Tang. And, so that's going to be very, very interesting. We also have a West and West corner as well. if you are tuning in and you are at the Engineer Summit, I, I love when folks will listen to Thursday, I come up and give me a high five. So I shake hands with new people and I give high fives to listeners of Thursday Eye. So please do not hesitate to come and talk to me about whatever you do and what I can do on the podcast to actually make it better for you. I actually ask it for many people. I was like, Hey, what can I do to make it better? And people was like, Nothing. You're perfect. That's not true. Come on. Are you listening to the full two hours? No. So this means there's something there to be done. with this kind of introduction, I want to say, a few kind of starting words. First of all, the podcast is sponsored by Words Biases Weave, which if you're in the Twitter space, you can see is the, the square black, colorful icon, which I will now invite as a co host. So it will help me. so shout out to Weave, for helping make this work, but also. We don't have any other sponsors, so the best way to support us, which is great if you want to do that, is first of all, if you're live on X or live on Spaces or whatever you are live with, come to this comment section on YouTube, on LinkedIn, on X, and just give us a comment, participate in the show. It's very, very helpful, especially, when I'm on LinkedIn. co host less sometimes like today, but also I would say, give we, we will follow obviously. and the other way to support us if you want is to go wherever you get your podcasts and give us a review, a five star review. before you give a four star or three star review, talk to me and tell me how I can improve. but after that, leave a review, absolutely. those are the best, to host to help support the podcast. All right. let's get started folks. I think like the biggest news of this week was obviously happening on Monday. Those of you who follow me closely already hopped on the space. We're on space live. some of us on Monday, we started our Monday with a president's day. some of us didn't have kids didn't go to school. The XAI team just worked throughout the weekend and we've been talking about XAI, working very, very hard, for a while and we were waiting for Grok 3. I was actually surprised that uncle Elon is actually releasing Grok 3 at this time. I was very surprised. Grok 3 was actually announced and demoed and then released fairly quickly to many, many people. So let's talk about Grok 3. Should we watch something? No, we shouldn't watch something. Let's just talk about it. a few folks, Igor Babushkin, Jimmy Ba, and I forgot the third dude's name, and Elon Musk, all sat down in a very similar to OpenAI announcements, setting, a very, very similar one, and announced their latest and greatest state of the art, at least on some metrics. Those are debatable. We're going to talk about this. LLM that was trained on a whopping 100, 000 H100s compared to the previous one, which was a 2, which was okay, but not that impressive, was trained on around 16, 000 H100s. And so they announced their great, new L, how should I say, state of the art LLM. But not only that, like we expected, they also talked about reasoning and agency and agents, et cetera. So that was super cool. So let's try to break it down. Although we did not get a technical paper, or anything. So I don't even know the context length of grok. I hear it's big, but I don't know how big this is. They didn't actually mention this anywhere, which is interesting because we're we're used to the way Things are happening, but this, this didn't, didn't actually work out. So, let's talk about And folks, in the comments, I would love to hear your, your thoughts about as well. Because, well Mm, the jury's still out. The vibes are still vibing. And, I promise you a recap on Thursday and since Monday, I've been trying to play with GR a lot. but then, Igor Baskin from GR said, oops, we had a bug, and some of you got GR two, although the drop down. Picker showed grok three. So if you thought grok is lame, this could have been this bug. So that's confuses things even more. So all of the people on our timelines who complained about grok or said, Oh, it's not that great. they could have just received grok two. we're getting a live reaction here that says a developer has said that's 1 million token context, but in the app, it's limited. I haven't seen this myself. I would love a source for that. Actually, Rodri, thank you for giving us this comment. I would love a source for 1 million token. I saw someone said that the token size is huge, but I didn't see a confirmation from the folks. So let's talk about what we actually got in grok three. we got a new frontier, LLM, that does incredibly well on benchmarks. So let's take a look at this. They mentioned benchmarks at the beginning. they mentioned benchmarks, of the non reasoning rock, and they talked about MMLU and my IE. so let's take a look at those. And then they also mentioned the reasoning part, right? grok beta. Actually, I want to see the evals without the think because those are interesting. All right. we're getting impressive results on stuff like GPQA, for example. So GPQA is definitely a great, Google proof QA, which is PhD level understanding Okay, we're getting a source. That's awesome. on GPQA, Grok is, is receiving incredible results, very impressive results. we're getting 75 percent GPQA on Grok 3 Beta and then, 41 on Grok 3 Mini Beta. Compare that to 32 percent of GPT 4. 0 and 36 percent of Gemini Pro. very impressive results. I actually like Also, they, maybe I'll show this, yeah, I'll show this, give me a second. I want to show you the stats here, on the video as well. So we're getting impressive results, and also I kind of like the way they present them as well. So you can hover over like each little column and like the column highlights. So whoever did the UI for this one, I appreciate it. As somebody who reads eval tables, the UI for this one is very appreciated. because, Not always they're state of the art in bold. what else do we have? We have MMU pro, which we know is saturated. Both of these models that are like 78, 79 percent with GPT 4 at 72%. And I believe that this is without the reasoning. Oh, wait. Okay. Yeah, we have a confirmation. It is one million context windows. Okay. on the official blog, context window, one million tokens, eight times larger than previous models. so thank you for folks. Roger was, you were correct. we got a confirmation, a context window, one million. That's impressive. this is a big model trained for a long time on a very big cluster. So this makes perfect sense. And still very, very, they also posted long context evals, loft evals for 128 context. Grok achieved the state of it accuracy, which is great. I haven't heard about Loft Benchmark before. We talked about other ones, but I haven't heard about Loft. They also announced that they have been trading on LMSYS Arena under the name Chocolate, under the code name Chocolate, and they're now topping the LMSYS Arena at around a 1400 ELO rating, which is the first time any model broke through 1400 ELO rating. I will say. that we have been talking about LM Arena for a while, and sometimes there's signal there, and sometimes it doesn't really correlate, because, odds on it, 3. 5, is way, way lower in the arena, but still, many people swear by this model still to this day, even though it was released, trained eight months ago. and so Arena doesn't really show this, and Arena shows, Gemini model, and I know some people don't trust Gemini models, although I do love them. Arena is not necessarily the best representation of vice, but it definitely there's signal there and 1400 yield score means that many, many people just significantly preferred Grok 3 on top of everything else. And what the XAI folks claim that this is an early version of Grok 3. Early means they keep training this, and they released a version that's smart enough, but this is definitely not its final form. very, very interesting. at this point, I would love to invite some folks in the comments to tell me, what's your experience with Guac, folks? I'm actually going to be okay with inviting some folks on stage here because, I want to hear and let me see if I can invite a few of my mutuals folks that have been playing with Glock. So if you're a mutual, welcome to step up. But, I've played with it, and here's again the kicker. I don't know if I played with Grok 2 or Grok 3, because they had a bug. And, if I did, it's a, not a very, it's an impressive launch, don't get me wrong. The model's impressive, but the fact that, I don't know whether or not I played with the right model, and I'm not able to tell you. my experience, if it applies, it's it's sad, but, we can actually try this live because, I tried it live on the, on the live stream and, it didn't work that well for me. Grok is now launched for free, by the way, you can choose Grok 3 Beta from the drop down and, Grok is now, free. They said that they will offer Grok for free for the foreseeable future until their GPUs melt and you can access grok on, up on grok. com and actually you can see it through, the grok interface. I want to test Grok on the question that I always have, which is Beth's Ice Cube. And I did test it, and you guys know this question from AI Explained on YouTube. I used this question on grok2, and it absolutely failed it, and it was hilarious the way it failed it, so I really want to see grok. com, and it's hilarious that it failed it, because the thinking got to the question multiple times, You can definitely see the Grok is super fast, even without the thinking part, and we're gonna add the thinking part as well. yeah, now that I am getting Gok3, I'm still receiving wrong answers. you guys know this question, for the folks who are now watching, I'm gonna, read this question again. Beth places four whole ice cubes in the frying pan, and then it goes into very unnecessary detail that says, at the start of the first minute, then five at the start of the second minute, and then some more at the start of the third minute, none at the fourth minute. The average number of ice cubes per minute placed, in the pan while frying a crispy egg was five. How many whole ice cubes can be found in the pan? So basically this question doesn't really matter. If you read into it, you understand that the second you place a ice cube inside the pan, they melt. So the question at the end how many whole ice cubes are remaining is confusing because all of the LLMs are trying to be very helpful in the calculation, go deep into the math of the rate of melting, et But if you read the question as a human, you're like, Whoa. Ice cubes melt, even if you leave them the counter at room temperature. Ice cubes will absolutely melt in a frying pan that fries an egg. there are not going to be any whole ice cubes, so the answer is zero. But this tricks LLMs to start calculating, and they give you calculations. we've been testing out on this and other questions, so the logic, the real world understanding of LLMs, and Grok has failed this one, and it's unfortunate. after Grok announced and now we know that's a hundred thousand, a hundred, one million contacts window, Grok also told us about, there can't be a model without reasoning in 2025, right? So they've announced Grok with reasoning. They call it Think. There's a button there that says think. And this one shows you the thinking traces and this is a reasoning model that was trained on verifiable results, kind of like, with the same RL as O1, as R1, as Coenquial, as like all of these reasoning models. And, you can see the thinking Elon Musk confirmed. that this thinking is not the actual traces. they're doing the same thing that OpenAI does. They are not showing us the full traces. For those of you who are watching right now, you can see the thinking like flies. but it, it overthinks a lot. And even on this question, I think, the couple of times that I played with this, I saw that, it got to the right result and then kept confusing itself and kept thinking about whether or not It's right or wrong. So it's interesting that I've seen the right results show up and then still nothing like the model arrived at the wrong conclusion. so that's, that's very, very interesting. from the, let's see what we actually got. Let's see if we got the right answer. So I kept asking Grok and now I've turned this on with, With reasoning, and yeah, we got the wrong answer again. Answer C, 20. assuming the frying process spends 4 minutes, Beth plays 11 Ice Cube, blah blah blah, and, both average conditions, yeah. it's really, really bad. nope, I will tell it no, and then hopefully it will try to figure out why not and then answer. we've tested other questions like this as well, so on these questions, at least, the vibes are not great. I want to confess, I went to O3 mini, which we were celebrating, a while, and Ultra Mini was just launched from OpenAI, to big fanfare. Ultra Mini also fails this question. Although, O1 Preview and O1 gets this. And I think even GPT 4 sometimes gets this. is this your experience, folks? Is this your experience with Grok as well? because I've seen folks turn around on it. and this is why I'm saying the vibes are, the vibes are split. we actually have Akshay here. Akshay, have you had a chance to play with, with Grok? What's your, what's your take? Hi Alex. after a long time. Yeah, you haven't been here in a minute, man. How are you? yeah, I'm doing good. I did play with Grok a lot. And, only for coding. so sadly, nothing else. And, thinking mode off, because I don't like the thinking mode at all. I prefer the Gemini thinking mode or O3 Mini for that matter. But with just the base model of Grok 3, it's In my opinion, it's the best coding model out there. And, this is considered it. I don't do VEV rated coding. If you do VEV rated coding, I think 3. 5 is still better. But if you do AI coding, so if you write a lot of Python, especially if you deal with cutting edge stuff, so like something that has come recently separate that. I think Grok 3 is just really better than anything else out there. Before this, I was using Gemini for this because their knowledge cutoff was pretty recent and they can, get the updated stuff from internet and store it up. Yep. yeah, that has been my, basic understanding by far. maybe I'll have to switch from Gemini to Grok for my coding stuff, but, That's been pretty cool by now. That's very interesting, man. Thank you for chiming in. Thank you, Akshay. And, it's good to have you here and chiming in to ThirstyEye as well. again, folks, if you're Mutuals and you've been on the podcast, you want to share your experience with Glock. I'm still collecting vibes. you're more than welcome. I see Morgan. I see Noah. I see like a bunch of folks. Ishan. let's get back to Glock. Some of the stuff that they announced. they announced the thinking mode where you can see the streaming thinking tokens. and then they talked about some evals that are compared to, from the thinking tokens. And I actually want to run through those evals because then I saw a debate, about those evals. And this debate is very, very interesting. Let me see if I can pull up the, no, that's not what I want. Gimme a second, folks. I wanna show you the, the windows. Okay. why can't I gimme a second, folks. One second, please. the funny part about the new eval is that, XPI has also started posting very weird graphs. So if you notice. the way they plot the graphs, the scales are different for each plot, right? So they make you seem the difference is larger than the numbers suggest, right? Like it went from 87 to 90, but the bars for these two will be completely different. Google used to do this and people used to call out Google on this. And even Musk, I think had posted a few times trolling them. And now XAI has done the same thing with their latest evals, and they have completely left out, O3 from their evals, which they should have included. Yeah, so we can talk about this. Just wanted to mention it. Because they did release, a state of the art model. And then they did not add all three. But then also I saw some comments saying that all three was not released yet and may not be released as well. So the admittance potentially makes sense. I saw this. you're right. There's a whole conversation about the cat in this I'd usually love to cover this, but the academy has started happening with Boris, from OpenAI and, Aiden, McLellan, that's now in OpenAI as well, started calling out some of these graphs, specifically, the graphs that add, the reasoning and also the graphs that add, best of N scores. So I think here's one example of, this conversation, basically somebody said that, The lightly shaded parts of the evals. So on AIME 25, AIME is competition math. they showed a specific example from Grok saying that, the model generalizes and it's not that they just trained on this data because AIME came out a couple of weeks ago, or at least this part, and they showed a impressive 93. Results out of 100 93 out of 100 means they solve 93 out of 100 questions, or 93 percent at 100%. I'm not, entirely sure what they're showing. Then, there was like two bars on the same bar. There's the regular color bar that gets up to 75 or something. And then there's a lightly shaded part of the same bar that goes all the way up to 93. And then somebody posted and said, Hey, the light blue part is actually best of N, which means the grok 3 reasoning is, like reasoning for multiple times. And then they select one of the 64 one, for examples. And, and they show that without this best of N, this is the same model as O. One, level, which that's not what Elon Musk wants to, wants to say. but then some other folks chimed in and said, Hey, OpenAI, you guys also did this. You also showed us best of N for AIME because, we're not looking at one shot only. We're looking at models that can do multiple, multiple things and then get to the right result. like very similarly to. Weights Biases trying to get to best of 3 bench, which we talked about, right? Sean, the CTO of Weights Biases, did a lot of iterations to get to that level. but basically, basically, people started to talk about whether or not these vibes are, correct. And then, XAI folks said, you OpenAI did the same thing with 03, 01 and 03 as well, but not 03 mini specifically, there's definitely a conversation about this, and, some people are very salty about the way that OpenAI treats, some folks publicly from OpenAI, treat the, the conversation now that they've potentially lost, the leading run, at least for a little bit. Now, back to Grok. I'm trying to see, and I asked yesterday, there's a bunch of very smart people here in the iEngineer Summit in New York. I tried to collect vibes. You would be surprised how many of them never tried Grok before. this could be the result of, Musk specifically. This could be the result of people not trusting. Somebody asked me yesterday. if Grok is full of Elon Musk policies, and it was an interesting question. Yeah, I just wanted to mention that I have had premium for a long time, like Experian and I did not use Grok at all. Not at all. I would rather use when 1. 5 billion on my local system than use Grok two, But Grok three will probably change it. And it seemed like a nice rolling model and conversational model, but it was not a nice problem solver or a coding model, right? That seems to be changed with Crock3. By far in the past few days, I have found it very helpful with coding and, yeah, I'm right now using it with coding. I hope it comes in on the, on the, IDEs, so cursor and PS code, hopefully, that we can like truly experience what it's capable of. But until now, the wives are, that it's, it's finally a problem solving model. It was not before. It's finally now. Yep. And I, I should mention, that API, they mentioned that API is coming, but there's no API right now. So even on the inability to evaluate right, like right now, we're not able to plug this in and test for ourselves whether or not the evals that they're giving us are correct, which is something that we usually love doing independently. so right now there is the model. A model is available on x. com for I think everyone right now. So they first released it to premium plus subscribers. Then they also announced a tier on grok. com. but then, they currently do not have, the API access for it. So we're not actually able to use this model to independently evaluate this model and to to tell you guys whether or not they actually, told told us the truth. actually, I would agree with you like this. I've used work before and I mentioned this multiple times in the podcast. I use rock for real time information access. And I think it's unparalleled at this specifically because it has access to X info at real time and also has access to read it and like a bunch of stuff. and similar to this, I will also say the thing that they released is deep search, right? So you guys remember deep research from open the eye. That's now still available on, the premium, sorry, the 200 plus plan. that's definitely something that we've been covering. It's open the eyes agent. and when the grok XAI team in the announcements got to the agents part, they said, Hey, we also think about the agentic future. Our first agent is. the research agent. Very similar one to perplexity. Similar to deep research as well. they go, they check a bunch of sources, they reason through them and they kind of like go deeper. although I did have funny responses with this one, I called it shallow search because I asked for something fairly complex where deep research from OpenAI gave me 11 minutes and 70 sources, 17 sources, and, Grok searched for all of 34 seconds and they gave me a result that I called shallow search because it's it's, it was kind of not, not, not very impressive. I want to welcome Nuo as well. What's up, Nuo? Hey, what's up, Alex? It's been a long time. Yeah, it's been a minute. Thanks for joining us. Nuo is the dev advocate or open source advocate at 01AI, at Yeemodels. And welcome, man. What's your, what's your take on the situation? have you played with this? What are you thinking? So I've been trying with this grog view, thinking, method and, I think I have some very interesting, observation. it feels like more like a scratch pad rather than thinking. So I'm actually comparing it against the DeepSeek R1. And I think the R1 to me more someone who is talking to himself inside his brain. so it's more like someone talking secretly inside their brain, while Grok feels more like a scratch pad. it doesn't make me feel that it's like reason and then the output and however, if we really compare with the GPT 03 mini and it feels like something also different. So the 03 mini feels it tends to not overthink about things, but those two tends to overthink about things. So that's one of my very interesting little observation that I have. I agree with you. Absolutely overthinks, as on. My, on my kind of questions, I saw it and I think I posted about this. I'm actually going to add this to the show notes. I posted about this. It got to the right answer and kept thinking and multiple times and maybe four or five. I haven't seen this before, like almost four or five times. I've seen the wrong answer. So the right answer show up. and it's been, it's been a pain to read through this. It's no, you're almost there. No, you're like, you got it. Nope, and you didn't get it. so that, that was upsetting. but yeah, generally I think it's a good model. It's been trained for a big amount of time. One million contacts window, now we've got it confirmed. We're just waiting for the API. So to recap GROK 3, One thing that I will say, they claim that this is not its final form. They also claim that, they will keep releasing better rocks. I tried to ask Igor Babushkin somewhere, whether or not they're going to version this for us, or will they just replace the model that's on production? And we won't know and we'll just receive a better GROK. I did not receive an answer. so waiting, waiting for this answer. also as we talked about and Elon Musk promised the previous version will get released in open source. So they confirmed that once GROK is stable and live, we'll get GROK 2 as open source. I predict, and this is not my prediction, it's Ivan's prediction. I think it's dope. But I also don't necessarily think that everybody's gonna be excited to run this like it's probably gonna be huge. It's maybe an MOE. And so I doubt that like people actually run this, but the commitment to open source is remarkable, worth noting and shouting out. So we're looking forward for that open source grok to coming out soon. I think we've covered grok enough unless there's more Things that you guys want to put in the comments, it feels like we've covered Grok enough. I want to run through some updates and also introduce our guests for today's podcast as well. then we're going to go from there, let me actually run through some of the open source stuff that we have to cover. briefly, we're at least going to run through them, and then, I want to introduce our guests as well. In the open source area, which we're going to cover in a minute. We have a very interesting attempt from Perplexity. They call it R1 7076, which is for those of you who haven't seen Hamilton. This is the year that the Declaration of Independence was signed. I think, yes, Declaration of Independence, so basically the year of the United States independence. they fine tuned the, what they call, I believe, the Chinese propaganda out of R1. I think they didn't go as far as this, but I think their CEO did, at least on X, they said a version of DeepSeek R1 model that's been post trained to provide unbiased, accurate and factual information, but basically they did say, like this is like very specific to Chinese, government and one China principle. And they want to have this model, reply that Taiwan is, not part of China, et cetera. So they try to, make sure the R1 gives accurate answers according to Western principles. And so they show some examples of asking about Taiwan independence and asking about, Tiananmen Square, et cetera. And then they talk about some post training. the approach there is very interesting. they employ human experts to identify around 300 topics. So I know of one or two, but they went all the way to 300 topics known to be censored by the CCP. And they built like a censored classifier, and they trained those out. and got a data set of 40, 000 multilingual inputs and outputs to, train out of, So it's very, very interesting that, they have, the ability to remove censorship from a model via post training. I want to hear from Nuo on this. Nuo, what's your take on this, 7076 approach from Yeah, I would say first of all, DeepSea They work in China and they have rules and regulations to follow. Sure. I understand that. I also noticed that R1 is to some extent, filtered on some, topic. So I'm not that against this work, but, I would actually prefer that they can actually disclose more of their details in terms of post training because it's very interesting to see, how they describe their methodology. It's very vague. Like how they prepare the data, how they actually, increase the size of data set and how they fine tune because, Running the R1 model by itself, it's already very difficult and very expensive, and fine tuning such a model, it's actually, if the number they show is correct, if they only fine tuned on such a small, I would say pretty over faded data set, and I'm not seeing a severe decline in terms of, all these different metrics like MMLU and mass. So I'll be extremely surprised to see how they do that. So I would hope that they can actually disclose more details, but unfortunately in these notes, so yeah. Yeah, so on MMLU, they barely have a decline from 90, 90. 8, they get to 90. 5. very, very small, decline. On math, they basically are, like, almost the same. They even got a little bit more on AIME, but, that's probably variance from 79. 8 to 80. but yeah, I, I agree with you. we need, we need to know more about this. But, very interesting attempt as well, because I do know that many people do not appreciate the kind of the, the, the non-Western kind of leanings of R one, although I don't think that, they only were able to train on the stuff that they know. it's possible that the model is leaning elsewhere, in, in other areas as well. yeah, unfortunately that's the world we live in right now, so we know we have to deal with it. Yeah. Um, so I think one of the things also that might be interesting. So if Perplexity really have that much, resources in terms of research, then I think one of the things that should have been doing is to start from continual pre train. so to my knowledge, so in order to prevent those on ethical or, let's say, unlawful content from showing up. so the pre trained corpora has gone through some kind of, topic clusterings and some kind of filterings. so basically they're doing is to overfitting, In the SFT stage, but if they can do, somehow from the pre training stage, to add some of, some corpora that is different, I think that's going to be more thorough as open source work. All right, We're moving on. Actually, we're moving on, so I'll ask you to comment on something else because we do have some guests here that I want to introduce in a second. There's a very interesting evolutionary genomics model from Ark Institute and NVIDIA called Evo2. And this is, like fully open with two papers, not one, two papers. And there is weights and data and training and inference code bases. So basically, we love to see these attempts. We've talked about evolutionary models before, and this one seems to be kind of state of the art as well. trained on 9. 3 trillion nucleotides, so not tokens, nucleotides from genomes, and they use striped hyena, which we talked about before as well, to like process, long genetic sequences and to enable analysis of complex genomic patterns. and, NVIDIA, I think they have a platform of theirs called BioNemo, and NEMO is the platform, BioNemo is like the biological aspect of it. They can accurately predict the effects of genetic mutations, including, other regions as well. As I've mentioned before, I'm very excited about the evolutionary stuff. sorry, genomics, evolutionary and bio models. I'm very excited to see like the transforming alternative architectures getting to these models as well. this is a 40 Billion parameter model. Yeah. Evil 240 B. It's available on Hagen face. If this is something that you're into, it's, it's very, very well checking out and shout out to the folks for this incredible, incredible effort. two other things. Super quick on the open source. I'm sure there's more and we will get to the video part after the interview. There's a bunch of stuff there, including Muse, et cetera. but in the open source, there's a new benchmark called zero bench, where the, it's called the impossible benchmark for VLMs. and, they basically say that all of the current VLMs get zero on this benchmark and you can see like an example of this, the very basic example, they have like a bunch of letters like scattered and they say, answer the question that is written in the shape of the star among the mess of letters. And I'm not sure looking at this myself that I can see which star they're talking about. So very interesting kind of like, visual benchmark because we need more benchmarks. But at this point it like 0 percent of, VLMs are able to, to get to this. And, last thing in open source, which is very, very cool, for, for at least for some folks, hug and face released the ultra scale playbook, which is training LLMs on GPU, like huge clusters. They ran 4, 000 scaling experiments, on up to 512 GPUs. Of course, nothing close to the a hundred thousands ones that, open The XAI team talked about at Grok release, but basically there is a playbook for a guide for building and scaling ultra large AI models on key considerations, best practices, data, et cetera. So shout out to Hug and Face. And if you work in a lab that wants to scale your own, this is definitely a great resource. Yeah. All right, folks. I think with this, let me introduce our, guests for today. Let me make sure that they're here. we have Nimit and we have Leonard from Haze. What's up, folks? Hey, guys. Good to be here. Hey, Leonard. Welcome back. Leonard, you've been here before. and then Nimit, I don't believe you've been here before. but maybe I'm misremembered, but I don't believe you've been here, right? Awesome. So welcome folks. I will let you introduce yourself maybe briefly, and then we can talk about some exciting stuff that you released before we continue with the rest of the show, because I want to be mindful of your time here, but also I'm very excited about, the, the stuff that you released, cause I'm also like looking into this, Leonard, how about you start first? Sure thing. Yeah. And Alex, I'm very excited for your talk tomorrow on judges and evals at AI engineer. So excited to see you in person. cool. Real quick intro myself. So I'm Leonard, one of the co founders at Haze Labs. very much steeped in the world of A. I. Evaluation and reliability and robustness. spent the last 5 6 years of undergrad and a little bit prior to undergrad thinking about these research problems, ultimately skipped out on the P. H. D. To start Hayes. if folks aren't familiar with Hayes, Hayes is a reliability and emails company. people probably best know us for our red teaming and safety testing work with a lot of big frontier labs. But we also think a lot about, What does evaluation look like in a world where, everybody has a very different definition of good and bad, and everybody has a very different AI application and use case for models. so that leads us to a lot of our work with Verdict, which I'll let Nimit explain. Yeah, and Nimit, how about you give us a little intro for folks who haven't heard you on the podcast before? Certainly, yeah. I'm very excited to be here on the podcast. I'm Nimit, I'm a member of technical staff at Hayes Labs. working a lot with Leonard and, before this, I spent a few years in the quant world. so I left, started to get into this space over here and, it's been, it's been super interesting. so like Leonard said, we're thinking a lot about, the problem of aligning these judge models to like customer specific needs. a lot of the papers in industry tend to focus on one particular benchmark or set of benchmarks, but a lot of times in real business use cases, the distribution is shifting all the time, right? So we want to think about how can we use very large foundation models and compose them in different ways to, continually adapt to users, new needs to come along. And so we built Verdict in house as part of this, set of experiments to try to understand how far can we push this infinite time compute. and how aligned can we make it. Yeah. I want to follow up on this because it's very interesting to me. And also like I researched a bunch for this, like upcoming talk, like I mentioned, so folks who are listening and are in New York, you're more than welcome to like tune in. Actually, it's also live on YouTube. So I'm going to add the link to the show notes. And if you're watching on Thursday, you're welcome, to tune in as well. And let me know what you think. Leonard, last time you were here, we talked about it. attacks and universal jailbreaks. And by, by Jection, I believe that this is the latest research. How, how are you connecting the two pieces from the universal jailbreak world? And also I saw you guys were cited on the recent on tropic, universal jailbreak on a mitigation thing that we also covered. how, how are you connecting from that world of like mitigation and safety, et cetera, into the world of LLM judges? Can you make the connections to, for, for the audience? Yeah, for sure. by, by the way, the, the constitutional classifiers paper was a lot of fun to, to coauthor. We by Objection learning was actually, developed more or less, as a way to try and defeat that system. Yeah. 'cause it's input output classifiers. And so you can upsc the input and up classifiers and you succeed. but yeah, so of course his. is primarily known for our red teaming and the tax work, but, when you think about automated red teaming, you need to have a success condition, right? You need to be able to monitor the input and outputs to whatever target system you're testing and know, actually, whether or not you've successfully jailbroken that system, which is not a straightforward problem, right? in traditional functional verification land, you have things like branch coverage, code coverage. you have things like you, you can actually just directly cause a segfault or cause a set of unit tests to fail. Or, if you're in the smart contract world, you can actually, infiltrate and perhaps, actually get some money. So there's something very tangible and measurable that you can produce as a artifact to understand whether or not you've succeeded in your testing. But in AI land, it's much less obvious, right? And, people generically have been using things like patterns to try and see if there's an exact match on certain strings or using simple elements as a judge to determine whether or not the output of an AI system is, say, harmful or sufficiently harmful. A lot of what motivated us to pursue judging and reference free evaluation more was just that our red teaming algorithms were not like too much by search, prompt search or prompt optimization. It was mostly like, we could search really well, but what a judge considered to be a harmful response was actually not practically harmful or, practically harmful, executable or grounded in the real world. And so we decided, okay, we should probably just solve the first task of defining what is a good and bad response before we try and, Optimize with respect to that metric. Awesome. for folks who are tuning in and maybe have not a lot of ideas about like evaluation generally in the world of AI, I'll, I'll, do the very brief recap. There's basically three ways for folks to like evaluate, like you said, there's no unit tests for these models. It's impossible to unit test them because of the stochasticity because of like different temperatures, et cetera, because of complexity of agents, for example. And so what most of the industry now does. is one of three things. They either do, programmatic variations. They try to do with regex, like you said, or other ways, if your model returns code, they try to run this code and see if the code passes, et cetera. there's also humans in the loop, where people actually look. And you, I don't know, you pay, you pay a lot of money to scale AI or some other companies or your, you and your technical staff, you do it yourselves. You read through the, the model responses and you like try to judge them and write them in like an Excel sheet or somewhere. And there's also the more robust and scalable way, which is these models. many models are great actually at judging the other models, on outputs, and so you give them some conditions, some criteria, and you try to get these models. what the industry ably calls LOM as a judge for listeners of Thursday. I may remember the last AI engineer I showed up as, as an actual judge in costume and talked about lms, a judge, and, people now call me the judge because of it, including hamel. But, lms a judge. are problematic. They're problematic for multiple reasons, which we'll now talk to. And how about you take us into the world of like, why and some examples of like, why LLM judges are problematic? Certainly, certainly. to start with, LLMs as a judge have all the same Issues that LLMs have to begin with, right? they're super sensitive to the prompt to begin with, right? for example, if you ask an LLM as a judge, Is A a better response or is B a better response? The order in which you specify A or B actually matters a lot. There's a huge correlation that, most models, including models that are public that are released, and new and fine tuned and Tune very well, they'll prefer a over B, regardless of what the content is. Models will tend to prefer longer responses over shorter responses. And perhaps most interestingly, models will tend to prefer their own responses that they've generated out of their own distribution compared to other models. So if you're, you know, evaluating the output of an AI system, that's you know, interacting with a customer, for example, it will prefer content that it's generated on its own. So you have to be very careful when, aligning these models of these, these insidious distributional biases that all these elements have to begin with. And it's compounded even more by the general structure of these L. M. As a judge prompts and techniques that people use. So out of the box elements, the judges don't really work. They have a ton of pitfalls that you really need to be aware of and very carefully think through and try to mitigate this last one. I called, some folks refer to as nepotism bias models. Actually, I found it really funny. And this is a way, a good way to remember this. Like GPT four would prefer to be four out. So we're like that family of models, maybe not the one, and then you have to do some stuff to at least know about this and then try to mitigate this. and so this is in the vein of what you guys announced. Thursday is not a regular podcast where I invite guests of interest and ask them about just the general stuff. We talk about what happened this week. So can you connect the dots for me? what happened this week and why you guys are here? and let's, let's talk about verdict. Yeah, awesome. Uh, so real quick, we, Nimmin and I released yesterday, Verdict, which is our library for scaling judge time compute. so judge time compute is this new notion, right? Of course, we've had, at this point, two iterations of people pushing scale. So we've scaled pre training, compute, we've scaled inference time compute. but to us, as we think about where AI is headed, It's not necessarily generation that's the hardest problem, right? It's more about how do you prune and rank and filter and select the best examples, at test time for your particular use case, right? And so again that comes down to the evaluator, or in this case people call it verifiers for test time compute or verifiers for word models or whatever have you. right now we have not really pushed that far. beyond formal settings like programs or or mathematics, with these verifiers and what we're thinking a lot about is how do you get a little bit, softer, richer rewards in non verifiable settings, right? And we think that, actually pushing. Compute for the judges themselves. So just using more compute in the judges is one way to get on those rich rewards for your your particular setting. And so concretely, what we released is this library fully open source library that lets you stack together different primitives and patterns, derived primarily from the scalable oversight literature from the generative reward modeling literature from the critique modeling literature, in ways that basically lets you get 01 or 01 plus performance. for a fraction of the cost. so you can think of it as we're scaling inference time compute for judging, but with very strong architectural priors, that lets us be very efficient in how we use tokens. I love that. I want to follow up on the scaling stuff. because that has a very straight up definition, at least in the way I think about this, right? I've always added chain of thought prompting to your models and going to receive chain of thought back. the update in recent times with like inference time compute is that this kind of happens inside the model itself because it was trained with RL and now the model knows how to do this and then you can provide, like more and more time to think or to inference. let's say, and then the model basically reliably gets more and more correct on the data. But this is not necessarily what's happening here. unless is it like, if I want to understand correctly, what do you mean by judge time compute, which I love just I'm scaling. can you clarify what this means? Are you using reasoning models under the hood for this, or are you not using reasoning models, but trying to get to the same results by approximating what's happening within the model, but with just like some infrastructure. Yeah, that's exactly right. it's very much the latter. so I don't know if you actually Alex remember that sort of, 2d plot of performance versus latency and cost. Um, maybe if you want to pull it up on the, on the tweet thread. But yeah, the idea is very much that, you could certainly use reasoning models as judges. but they're very expensive and they're relatively high latency. which, in the grand scheme of things, maybe it's actually not terrible. You may be just like 2x, 3x training speed. nonetheless, it is still very expensive. And so a lot of what we're trying to do is match or exceed reasoning model performance as the evaluator, just by, yeah, as you say, stacking infrastructure in a way that is relatively constrained for the task. Yep. and so we are looking at the chart right now for folks who are listening, where, at least on the expert QA judge accuracy. 01 is absolutely kind of the highest cost, at least, but not the highest results, right? So it gets around 69 percent or something, at around the cost, like 176, according to what you guys saw. And then Verdict, which is a collection of judge techniques together in this case, gets higher scores, so almost to 80%, at around 50. So around a third of the price. could you maybe talk to how you got there and why verdict is the tool that allows you to get there? Maybe you take this one. Sure. Yeah. So concretely to answer your question, you're asking, do we use reasoning models or do we, do something else? And the answer is we just do something else. So a reasoning model you can imagine would try, under the hood. a bunch of different techniques, right? It would throw the whole kitchen sink at what might even be a medium sized problem and not like a large sized problem. What we actually do in this case where we achieve these results is we ask an LLM as a judge to provide an explanation of their reasoning and a score as well, right? Then we'll take a second LLM, And we'll ask that LLM, hey, does this explanation make sense? Is this explanation, coherent and logically consistent? Or does it contain hallucinations, right? And now we can use that extra set of supervision and run this experiment, in our case, three times. And then take an aggregate of those results, right? So we basically have decided that, the common failure case of the initial L, unless a judge, is maybe hallucinations, or, or maybe it's, it's not answering the task correctly, and we're pruning those results using the verdict system. So we designed a verdict architecture. and then we can just apply that across the whole data set. And now this verdict architecture is our judge. So it's the compound of many different small LLM calls, in this case, four O calls. And in this case, we do six different four O calls, three initially and then three verifies on those and then aggregate the results. So that's what we mean when we say we, we do compound systems and you can think of it as one possible thing that an O1 or reasoning style model might do. But we've decided through experimentation that that architecture will work the best on our judge task. So we don't have to do the whole O1 reasoning chain. We can just do this much, much faster. compound chain that we've designed ahead of time. I like some of the best practices that you guys have added as well, because, in this world, especially, and folks who listen to Thursday Night, they know, I work at Western Bios, we do, a tool set for evaluation and visualization as well. So we also research into, like, how folks approach, the main problem. of judges, that we see specifically is that how do you evaluate between the judges itself? What's meta evaluation? How do you actually know whether your judges better, compared to like your human raters or is it just like hallucinating more? So you get a higher score, but it's not in fact better. how you test for meta evaluation, how you actually know that the judges are good, you're just doing against. expert QA and judge bench and judge mark, all this stuff. Or do you have any insights into how folks that actually do want to look at judges and decide which are better? How can they, met evaluate the judges themselves? Yeah, that's a really great question. And I think this is actually like the last extant frontier of AI in general. Like I think this final customization, like final last mile customization and adherence of the judge. And then subsequently the underlying model is A perennial problem. I don't think anybody will solve this in perpetuity, but I think, verdict is an open source library for giving you the potential. It gives you the canvas to apply something right to apply a judge model, but you still have, throw paint on it, right? You have, constrained the judge basically tweak the parameters of the judge to something, right? And so that's a lot of what we think about commercially on his platform. perhaps worth mentioning in brief. We have this method called active alignments, which is shorthand for active learning to align judges to human preferences. we basically, have this human in the loop distilling a lot of their preferences and taste around a particular, response, right? Input output response, and we use that to update the judge over time, right? So I think, that is probably the best way to actually do the meta eval, so to speak, and see how well your judge really aligns for your particular use case. Of course, like the, most straightforward and perhaps gold standard would just be you collect a whole lot of data and then doing the meta eval on the data set. see how that turns out. But I think absent of this, which is often what we see when we talk to customers, this notion of seeing how often your judge aligns with the human preference on the fly in an online way is also very, very solid proxy. Yep. and, in our workshop that we also do about evaluation, we're going to talk a little bit about, Cohen's kappa and, ways to actually do inter, rater alignment, which is fairly standard in at least some of the more, I don't know, binary areas. In some others, there's some other areas, but yeah, I agree with you. It's a problem. And it's a problem that, once you start getting into this problem, you're like, okay, how do I evaluate my meta evaluators? are those okay? So that's actually interesting because you guys also have this, right? You have one judge that responding and then you have another judge looking at those judge. So just for folks who are getting confused about the amount of judges. There's the production model, that sits on your production, does, replies to your users, that could be cost optimized, that could be speed optimized, that could be like fine tuned, et cetera. there is the, the teacher model or the judge that looks at the outputs of your production model, decides, Whether or not they are according to criteria, which is maybe criteria of correctness, maybe, maybe bias mitigation, maybe toxicity mitigation, maybe like a correct summary, etc. Maybe your own evals, which we always recommend for folks building your own evals. But you're saying that there's like another layer of verification on top of this judge as well. And the output is the kind of the cumulative understanding of both of these. What are maybe some of the primitives that you guys built into Verdict allows to do this. Definitely. Yeah. So you explained it perfectly well. I would add that this is just one particular architecture that we found works well for a wide variety of tasks, right? But the great thing about Verdict is like, it's a true framework. You can design any architecture you want to. under the hood, we have basically a DAG, just a graph, of nodes, judge nodes, or other arbitrary. can do whatever you want them to do. and you can compose them and stack them and align them together however you like. and yeah, you asked what primitives we have and what those allow us to do. so for example, you can very easily do things like debate. which is the background of our website. The logo is just a debate going on. you'll have a proponent and an opponent argue about, is this this? Is this that? Is this correct? Is this not? And at the end, you'll have a judge take the output of that conversation and make a verdict, right? now you can imagine you might want to do that five times and take the average of it. Or you might want to do that five times, then filter them down by, Some other criteria, to avoid some biases. You might want to take A and B and then do B and A and then, take the average. You can really compose these however you like. And we hope that the community is going to take this very general, this general purpose framework and build all kinds of crazy, verdict graphs, and find out what works best for their use case. And yeah, there are a ton of ideas from the research literature that we have very easily been able to implement with this library. super easy to take your graph and adjust it a little bit. We have like airflow style syntax for actually aligning dependencies. So yeah, we hope it's just a very general purpose framework, basically. That's awesome. let's talk about some evals before we, I'll let you guys go. I want to talk about a few ones because you posted some state of the art or near state of the art results. could you walk me through them? and what do you think is like remarkable about this? So we're looking at Expert QA and this is like remarkable. You're getting like 10 points above 01. but also you have verdicts. below this with 4. 0 mini. could you walk me through what this means? the judge unit plus max pool unit. what does it mean? How you achieved like a state of the art on expert QA? And also I would love to talk about judge bench as well. Yeah. so real quick. The actual architecture that we use is six LLM calls here. JudgeUnit, JudgeUnit, MaxPoolUnit. It's really, three pairs, sorry, three sequences of JudgeUnits. So this is what Nimit was mentioning, where you have this initial judge, and then a self verify. we replicate that three times, and then we get the final results of each, judge then verify, and then we aggregate that using a MaxPoolUnit. MaxPool is just MaxVote. so there's six LLM calls in total. when we say, 0. That just means we're using GPT 4. 0 for all the underlying six LLM calls. when we say GPT 4. 0 Mini, that means GPT 4. 0 Mini is powering each of those six LLM calls. obviously GPT 4. 0 Mini is not as powerful, as GPT 4. 0 and As you stack GPT you get less of a good score versus if you stack GPT calls. Hence the, 12 percent discrepancy there. But for folks who are not looking, it's still better than just like straight up one shot GPT You're getting like 76 percent here versus GPT 64. And that could be attributed to just like multiple times you're aggregating results. Exactly. Yeah, exactly. and it's cheaper. Six GPT 4 mini calls is cheaper than a single GPT 4 0 call. it turns out this particular architecture, This judged and verified and aggregated architecture just generally works very well out of the box. we just threw it at the expert QA task and with no particular tuning, we were able to get close to 80 percent and beat out a lot of the other models on this task. That's awesome. let's talk about judgments as well. I've looked into, they are trying to collect examples specifically from STEM, related areas and they are tricky. for judges specifically. So they're looking at tricky for judges, like tasks. and, it's still getting saturated. Like the old one previously getting 75 percent of this, even this very tricky judging tasks supposedly is getting already very saturated. with this method, you guys are getting, very close to very close to sauna 3. 5, at 63%. Have you tried SONET specifically? how come multiple judgments and maybe let's talk about argument units as well. How come multiple judges are not getting the same level of SONET, for example, here? I would love to know. That's a good question. we need to do more investigating, but our initial hypothesis is The flavor of task that expert QA is very different than judge bench. there's something very fundamental, which is judge bench is a data set of synthetic generations. the actual inputs and responses are from LLMs. so it's synthetically created. But, like manually filter data set expert QA is all human generated. So all the queries are generated by experts. All the annotations, the labels, et cetera, are generated by human experts. so there may be, it may be one of those things where, let's say 01 or cloud 3. 5. Son has just seen a lot more synthetic data and been trained a lot more on these synthetic eval tasks. Not unreasonable, right? a lot of people are trying to bootstrap. like Meta has self taught evaluators, or, a lot of other people trying to bootstrap, online DPO their way on top of synthetic, synthetically generated data. so that could explain the discrepancy, in judgements results versus expert QA results. but that's just a, we ought to dig a little bit deeper there, but that's the initial hypothesis. Yeah. That makes sense. I think we're approaching the end. How can people use Verdict and where is it available and what are the plans for the future of Verdict? Yeah, Nima, you want to take this one? Sure, yeah. Verdict is fully open source. it's on GitHub. you can do a pip install and You can get it today. we also started out as an internal tool that we're using for our own research. and we have spent a good amount of time, making, some documentation, a bunch of cookbook items. And we've also, implemented, I think, six or seven. papers from, the latest LLM as a judge literature just showcasing all the crazy things you can do with verdict. So, we hope those are good starting points we have a discord, and we're always happy to help answer questions on twitter about how we use it and we'll also be releasing the source code of our actual verdict implementations for these state of the art results we have on our website over the next couple days, so we hope people just dig in and start using it. And I'll also add that, super fast. We have a thread based concurrency model lets you run thousands of, LM calls and responses and coordinates them all in parallel. Super fast. We can run these experiments blazing fast. either with hosted BLM models or with provider models. we support client side rate limiting. So you never run into any issues running large scale experiments. we really hope the community does something creative with it. There are a ton of applications, can fit into any part of a number of different research projects or production projects. So I'll go into my spiel here just to connect the dots. because again, from Raising Bias is an evaluation platform. And the whole thing is when I talk to AI engineer developers, they're like, I them how they evaluate, and they show me this thing, which means vibes. vibes evaluation is fine, but folks, you cannot compare the vibes of today to the vibes of yesterday. There's no empirical way to do arithmetic between vibes. You cannot say vibes yesterday were like at 70%. No, you need empirical results, you need evaluations. For this, you need LLM judges, and there's like a bunch of biases, and the verdict seems to be a great attempt at mitigating those biases. one last thing I would love to ask you guys. you did. Achieve SOTA on multiple bench marks, with the library, you have best practices that you posted. I would love to run through those best practices to just give something actionable to folks who are listening. How to achieve SOTA as LLM as a judge. I think it's on the documentation, but if you guys want to take one of each or like maybe like a few of the best practices and share with us, that would be amazing. Yeah, for sure. maybe real quick before I get there. I do want to point out like verdict judges are very ostensibly for auto evals, right? Like offline evals, sample evals, perhaps inference time, runtime evals as well. But we do see these judges as being very powerful for not just application evaluation, but yes, as rankers, verifiers, and pruners during test time computes, we see them as being very powerful as reward models during reinforcement learning. in fact, we're training our own reasoning model, using, verifiers, which I awesome. By the way, if people in the audience have tasks that they want reasoning models for that are not in a verifiable domain, please let us know because I feel like we're just on the cusp of wanting to try this or like the community is on the cusp of trying this, but there hasn't been, a canonical benchmark or canonical task that people moved towards, but yeah, you can use verdict judges any number of things, right? Offline. one of them in first time guardrails, modeling for reinforcement learning. And then the biggest point in inference guardrails that I heard coming from you is that if you do use reasoners, for example, guardrails is an impossible task. You will not run a reasoning model as a guardrail because it will take longer than the actual production model. It would make no sense to, you will not be able to block any like problematic thing. You have to have something faster. So getting to the level of reasoner with a fast infrastructure, you said, Nimit, it's paralyzed, right? So like multiple things running in parallel, you're not sequentially waiting for one judge and another judge, When you have a summary of them, so that I think is very interesting approach as well, because guardrails, we've built some guardrails as well. One big consideration is how fast they are, even to the point where LLMs are probably not necessarily the right choice for guardrail. You need to train like Bert or modern Bert, specific classifiers, like we said, because LLMs sometimes are even slower. so yeah, that, that's one definitely big, big approach. And so basically, I get what you're saying, like verdict is not necessarily only for offline evaluations. It could be used for RL, and you guys are working on this, and maybe we'll have some follow up on this. best practices? Yeah. Nimit, you want to play through some of them? We can trade on and off. Sure. I think the biggest point to make is that it's all about the distribution. It's all about the distribution of the models in your pipeline. like I said, we've learned a lot about how these different models have their own distributional biases. some of them, they have like mode collapse. They'll say yes, a way bigger percentage of the time than no. one thing that we like to do is study like the actual log prob token distribution as opposed to relying on things like structured output. Not a lot of people talk about this, but structured output imposes its own set of biases on the output, right? structured output needs to mimic, things that seen in the training data that are also in Jason format or XML format. And those documents have a very different structure than like the space of natural human documents or thoughts or alignment values, right? So it's all about distribution. It's all about, making sure that you're studying the distribution of your outputs at every step of the way. similar to a lot of like classical machine learning approaches and being very careful and making sure you don't get misaligned at any of those stages. So a lot of our soda tuning that we did was like studying these things carefully and making sure our models are expressive where we need them to be awesome. All right, folks, this has been great. Thank you so much for coming up and open sourcing verdict as well. I think it's very important to have. I'm looking forward for some amount of integration from our folks to like show verdict results with a nice dashboard as well. So I think we have a conversation about this. Meanwhile, I will tell folks that check out Hazelabs, you guys are doing awesome work. I really appreciate when you come, there's always something to learn from. And I definitely come from this, more. so Thank you for coming. We'll continue with our other corners here. but, folks should definitely give you guys a follow and then, check out verdict and give us comments about verdict as well. if you guys like, like Leonard said, have a, tasks that you want to reserve to do. They're not in verifiable domains. This will be a big unlock once there's RL for non verifiable, results, possible to train, for reasoners. Hi, folks. Thank you so much for coming. We're going to continue with our show. and the next thing we want to talk about is, I'm sliding into naturally towards this week's buzz super quick, right? So folks who are listening to Thursday Night know that there's a corner there called this week's buzz where I talk about everything related to weights and biases. Let's do this super quick and then we'll continue with the show. Alrighty, super quick. I don't have a lot to update you on what's in my corner besides the fact that our workshops are sold out. So I cannot invite you anymore to Toronto workshops that I'm doing in a couple of days. But if you are listening to the show and you're coming to workshops, that's going to be awesome. I'm looking forward for this. We are here. at AI engineer summit in New York. We're sponsoring this, awesome, awesome summit, conference. It was like the top AI engineer conference in the world. so please, if you are here also, and you're listening to this live, you probably at the conference right now. So go focus on the conference, but if you're, if you're there. Come up to our booth. There's five of us. We love to talk to as you heard just now, we'll have to talk about evals. We will have to talk about, just observability in general, LLM, AI engineering agents, all of these things. we are looking forward to speaking with all of you about those topics at the AI engineer conference, which is. Awesome. Again, so shout out to, to, to the folks that, SWIGs and Ben and everybody who organizes this incredible conference. We are also, I'm having a talk tomorrow. Tomorrow's. Friday. So my talk is 11 a. m. Tomorrow. I need to still prepare for this. As Leonard mentioned, I'm going to do like an analysis and research into whether reasoner models are better. LLM judges, as we saw, at least in the expert QA example that Leonard posted, they are, but it's not Entirely the full story. So if you're interested in a little bit of my research and like the approach that we have into understanding judges, more, more than free to tune in, I'm going to add the link to the show notes, but it's on the AI engineer YouTube channel. It's going to be at 11am tomorrow. and, so those are the things. And then the last thing that I want to tell you before I move on is that we. released. We're leaning into agents folks. 2025 is the year of agents and reasoning and agents at work is the name of this AI engineer conference. And we at Ways and Biases are also leaning into agents. We want to understand where we fall short, et cetera, on agent evaluation and agent observability. Which is, a topic that everybody's asking us about. So we've released the agent white paper. It's on our socials. You're more than welcome to check this out. And we're also are doing a agent's course in collaboration with open AI. with Ilan Biggio from open AI, we're doing an agent's course. So one B dot me slash. This is the way to pre sign up to our course. And I know folks are loving our courses, especially folks who are listening to Thursday. one B that message agents is the pre sign up for our course is going to get released, very soon. Talk to you practically about how to build agents with observability in mind and variations as well. if you're interested in any of this, please check out our socials on 1b. me slash, or sorry, the weave underscore WB on Twitter, which is if you're listening to the show on Twitter spaces, it's cohost. And if not, I'll add this to the show notes as well. So this has been this week let's talk about the rest of the stuff that happened in this week. So we had the interview because I had to be mindful of my guests. time. But let's talk about the rest of the stuff that happened in this week. Open source AI. Let's get it started a little bit about the open source LLM area. But there's a bunch of open source that happened, that are not necessarily LLM related. And one of the hugest ones Microsoft's Muse, Microsoft Muse is It's honestly crazy. the videos of this crazy. let me make sure that you guys are watching what I'm watching. they have built and released the model. So while Nissan figures out the, the, the feedback situation, I want to talk about Microsoft Muse because it's mind blowing. basically I'm going to share a friend of the pods, Rowan Chang's kind of tweet about this. Microsoft released a model that can generate minutes of gameplay from a single second of frame and controller actions, which is. Again, I'm going to say this slowly, you give it like a single second of a gameplay of any type of game with all the screen elements, with percentages, with health bars, with all of these things and their model generates a game that you can control Which is crazy. have you seen this? Now I can't hear you. I cannot hear you at all. Listen, microphone's off. Um We'll, we'll solve it, folks. We'll solve it. this is my, kind of like, traveling conditions as well. You guys should see the setup. I'm here in this hotel room with, multiple things. we'll, we'll figure this out. the, the cool thing about this, I, they call this WAM. World I have, I have, I have it somewhere. Let me, let me see. World, human world and human action model. Yes. Thank you. Thank you. Actually, world and human action model. It, it's the 1.6 billion parameter model. It's pretty cool. I've played with it before. And, have you generated Pretty cool. Have you generated, a playable game? No. No, that is not, No, that is no, not but the, but the, so we had, so I don't know if I'm supposed to say this, but like we were working with Qualcomm recently and, they had access to this, WHA model, a variant of this is it, 1. 6 billion parameter model. And it's, it's pretty cool. Like for its size, it's just, yeah, I can just say that it's very nice. Yep. So they, they obviously have access to. Yeah. Is my audio okay now? Oh, okay. I saw someone drive on that, drive around the city, and, first I was like, what are they doing with the wheel? Why is it so slow? But then they're like, this is all generated. So that was, that was pretty nice. They were using a little driving simulator and trying to drive around and generate a city, which was, It's progressing pretty fast, eh? It's crazy. We saw, we saw Doom at first and we were like, okay, but it still looks weird. But now it's started to become a thing. Yeah, it looks like eventually UIs are just going to be completely fully Generated, not fully composed. That's, that's what Jensen says, right? Jensen always talks about everything you'll see will not be rendered, will be generated. This is in the same vein. and yeah, this is a tiny model and it's, the cool thing about this is finally like it's, it's open sourced. it trained on one billion plus gameplay images, because again Microsoft has Xbox and the cloud. and then it learned from real Xbox multiplayer matches. Which is, I found it super cool, so if you played Xbox, lately, you know that, you probably are ending up in this model as well, and you can play with it, it's definitely, absolutely, cool, we also have some state of the art video stuff as well in the, the open source, model, so skipping from, what else is interesting about Muse, because before we skip, Yeah, it's, it's open availability and open source. And you can play with this. And, I don't know how game designers feel about this one specifically. but hopefully this will allow them to maybe explore their games before they fully complete. A small point that you can run it in a treacle lab notebook. If you, if you want. That's awesome. Yeah. send it. We'll add this as well. Um, the other thing in open source, sorry, I can relate to you guys on departure too. Because their team has been on a roll lately. we didn't actually cover it last week, I believe. Yeah. it came up randomly. It's almost, it's becoming like practically usable now, like not just as a demo that works, but. It's starting to look like it's deployable. So only positive for folks who don't know what this is. So it just draws squares around. it's not that different from having a language model and, a projector and a visual, like a clip encoder. And so you have a visual model projector, and this is how an LLM, and this is how most of the multimodal ones are. not all of them. but what this one does is it outputs the coordinates for the squares and for the rectangles and the color of the squares and the labels, on the image itself. And now it's very accurate, and in particular, it was accurate with spreadsheets and being also able to tell all the empty cells on the spreadsheets. So we might finally start to Automate, accountants after 40 years of trying. Just as we're coming to the tax season, I don't want my account to hear about this. actually I need to go find one. so Omniparser is a GUI control library and, here's a great result. I just took a screenshot of our interface for, StreamYard where we record the show and I just pasted in there and it looks nuts. Like they detect every little button in there. They detect every little kind of, just every little thing in this. detected. So basically you can then use this to control your mouse. and this is similar to what operator is doing. they call it computer use agent core. so this is similar, but only parser is in the open source. You can run this yourself. You don't have to go through a specific open AI model. So this will be used for controlling your. I used OmniParser 1 and, it looked very cool and it was impressive, but, It wasn't that reliable, so it wasn't always accurate. You had to often, go back on whatever actions you clicked. but this one is looking much more accurate. yeah, this might be the one that actually starts getting really, really deployed. Might even rival whatever, the MCP protocol, whatever cloud was doing with computer use Yep, alright, so we're moving on, so Omnipartial 2, definitely check it out, it came out February 16th, so yeah, within our time frame, we're moving on, to the video stuff, there is, there's two very interesting things in video, and, I want to talk about like the, the state of the art video, 30 billion parameter text to video model, which 30 billion parameter for text to video is huge. Most of them like five, six, seven, like 12, 13, step fun release step to video T2V text to video. and they also step to step video T2V turbo. they released both of these, these, Look, there is papers with a bunch of, folks, 204 frames in length. and then they also have a turbo version and I want to show some videos here. They look quite good. I'm, I'm very like. lemme see if I can, dude, this is MIT license. I'm just checking. Yeah. Hugging face. Now MIT licensed. Yeah. is MIT licensed video model That absolutely looks and does text as well. So here's an example of text. Which we are seeing a video of a Chinese girl opening up a scroll and on the scrolls written We will open source and you can see the text expand as she opens it. It's very like very realistic in nature Those are very short frames They also have we're looking at the video of Steve Jobs for example talking as the camera kind of rotates around him and then behind the Scenes it says like step video is coming on the actual screen and there's like Apple logos that are True to nature that looks like Apple logos. so for an MIT license, we're also looking at a, a boy turning into, venom from Spider Man, and like dripping like what signatures. This is an MIT license video model, that also has a turbo variant, and also a technical report as well. So if you're, if you're into this, I specifically think they're highlighting the text. if you're into this, the previous, this, State of the art, I believe in open source video was who neon video, which we're gonna talk about next as well. But Stefan, 30 billion parameters is not a small model by any means. it looks dope. so shout out to folks. It looks like the Chinese. labs went ham this week with a bunch of releases because, it uses almost 80 gigabytes of memory to generate, let's say 400 frames or so. So less than five seconds. I believe less than five seconds. Yeah. So very close to, Oh, no, sorry. Eight seconds of video, eight seconds of video, which is like what the state of the art of video releases. So that's step one. And you can actually try this. they have a link to try. we'll add to the show notes as well. So you can try and generate a bunch of videos on un. cn. And then you can see like other generations here as well. And they look good folks. They look good. very impressive. This is pretty cool. It came out. Right before Sora came out, people would have lost their minds. Yes. If this comes out before Sora was announced, people would have not, get excited about it. I will put some videos in the newsletter, in the show notes. They look awesome. Very much trained on Hollywood films. I'm pretty sure that, nobody here cares about copyright. yes. And the fact that it's open source, I will not mention this directly, but you know what this means. You guys know what this means when you can fine tune on these models and then people release all kinds of all kinds of things. so the other thing that I wanted to mention also in video is that how AI, released fast video, which is making HY video three times as fast with no additional training. So you guys remember this whole, This whole area where stable diffusion was released and the stable diffusion turbo was distilled from it and was like way, way faster and then flash is the Excel like all of these, we talked about multiple iterations of diffusion models getting like faster and faster and folks just once something is released in open source, we've seen this with R1 right now we've seen like perplexities is getting R1 and fine tuning this. Once something is released in open source, this is how the community then comes in and like tries to extract this. So fast video, released a version of H. Y. video from Huion, which is just three times as fast. And it looks pretty much the same, almost entirely the same. So we can see an example. And on the left you have the Huion video and takes 15 minutes for eight seconds. And, this model gets pretty much the same results with just five seconds. this doesn't require they use sliding tile tension to reduce the inference. and they also made other models also fast. and they have open distillation methods. So this is a distilled version, right? Do not be confused. But now there's a way here to actually improve without fine tuning, with the sliding, tile tension, which is zero quality loss, no extra training required. This is crazy. isn't this this is like rope. Remember rope when it came out and it had, this one word trick that you can use to extend the context length of the model. This feels like this for speed. Yeah, they're using a FSDP for training too, which is interesting, because it's the same technique that a lot of language models use. So I'm interested to see like how, how are they targeting layers in it for, for this? it's very interesting, at least from the GitHub there, it looked like they were borrowing a lot of the techniques and putting them together. I'm just wondering, that's five minutes for an 8 second video on what GPU, but it's probably just a household, GPU, yeah, it's my video. I think people got it down to a household GPUs, but I'm not entirely, I haven't run it myself like locally, I just run it like in the cloud. So they call the sliding tile attention and then, they say accelerate attention alone by 2. 8 up to 17x over flash attention 2 and, from 1. 6 to 10x over flash attention 3. So they have a very specific like attention mechanism for this thing, which is, I think, like absolutely dope. and they released it open source and you can use it. they basically, they call it a kernel, and then you can download this in their GitHub. So we'll add this, as well. And then you can inference with the Sliding Tile Tension. now you just need a, a half a million dollar book of, H200s at home, and you can play director in it. Yeah, you can do it. It's just cut and move. So I will say another thing that we glossed over, Nissan. I don't know, remember if we talked about this. HY video, Hunion video, supports Loras. So this is because this is an open source one, you can fine tune. H y video to whatever you want. And if folks want to go a little bit, and, not safe for work or not safe for podcasts, civet AI, if you go there and you just look at Laura's for H y video, you will start to understand why some, like a lot of people who want waifus, they want videos of those waifus doing all kinds of things. And so H y video is now trainable. You can, not only do an SFW work, you can also do. Celebrities, for example, you can do yourself. You can train a video model on yourself, which is, right now, only TopLabs kind of support, and, so this model, this distilled, version of Sliding Tidal Tension, now also supports the HY Loras, so that's cool. You can, generate videos based on your own stuff. We're moving on because the last thing that I want to talk about here, before we get to, tools and others and we conclude the show because also, engineers in town, figure just announced breaking news today. Let me actually want to use breaking news button. AI breaking news coming at you only on Thursday.