Episode Summary
Welcome back to ThursdAI! And wow, what a week. Seriously, strap in, because the AI landscape just went through some seismic shifts.
In This Episode
- 📰 📆 ThursdAI - May 1- Qwen 3, Phi-4, OpenAI glazegate, RIP GPT4, LlamaCon, LMArena in hot water & more AI news
- 📰 Qwen 3 — “Hybrid Thinking” on Tap
- 🔓 Other Open Source Updates
- 🎨 Big Companies & APIs: Drama, Departures, and Deployments
- 📰 Farewell, GPT-4: Rest In Prompted 🙏
- 📰 The ChatGPT "Glazing" Incident: A Cautionary Tale
- 🤖 BREAKING NEWS: Claude.ai will support tools via MCP
- 📰 Google Updates & LlamaCon Recap
- ⚡ This Week's Buzz from Weights & Biases 🐝
- 📰 Evals Deep Dive with Hamel Husain & Shreya Shankar
- 🎥 Vision & Video: Runway Gets Consistent
- 📰 Runway References: Consistency Unlocked
- 🔓 HiDream E1: Open Source Ghibli Style
- 📰 Final Thoughts: Responsibility & Critical Thinking
Hosts & Guests
By The Numbers
🔥 Breaking During The Show
📰 📆 ThursdAI - May 1- Qwen 3, Phi-4, OpenAI glazegate, RIP GPT4, LlamaCon, LMArena in hot water & more AI news
Hey everyone, Alex here 👋 Welcome back to ThursdAI! And wow, what a week. Seriously, strap in, because the AI landscape just went through some seismic shifts.
- Seriously, strap in, because the AI landscape just went through some seismic shifts.
- This week felt like a whirlwind, with open source absolutely dominating the headlines.
- Qwen 3 didn't just release a model; they dropped an entire ecosystem, setting a potential new benchmark for open-weight releases.
📰 Qwen 3 — “Hybrid Thinking” on Tap
Alibaba open-weighted the entire Qwen 3 family this week, releasing two MoE titans (up to 235 B total / 22 B active) and six dense siblings all the way down to 0 .6 B, all under Apache 2.0. Day-one support landed in LM Studio, Ollama, vLLM, MLX and llama.cpp.
- Day-one support landed in LM Studio, Ollama, vLLM, MLX and llama.cpp.
- The headline trick is a runtime thinking toggle—drop “/think” to expand chain-of-thought or “/no_think” to sprint.
- On my Mac, the 30 B-A3B model hit 57 tokens/s when paired with speculative decoding (drafted by the 0 .6 B sibling).
🔓 Other Open Source Updates
1. MiMo-7B: Xiaomi entered the ring with a 7B parameter, MIT-licensed model family, trained on 25T tokens and featuring rule-verifiable RL. (HF model hub released Helium-1, a 2B parameter model distilled from Gemma-2-9B, focused on European languages, and licensed under CC-BY 4.0.
- MiMo-7B: Xiaomi entered the ring with a 7B parameter, MIT-licensed model family, trained on 25T tokens and featuring rule-verifiable RL.
- (HF model hub released Helium-1, a 2B parameter model distilled from Gemma-2-9B, focused on European languages, and licensed under CC-BY 4.0.
- They also open-sourced 'dactory', their data processing pipeline.
🎨 Big Companies & APIs: Drama, Departures, and Deployments
While open source stole the show, the big players weren't entirely quiet... though maybe some wish they had been.
- While open source stole the show, the big players weren't entirely quiet...
- though maybe some wish they had been.
📰 Farewell, GPT-4: Rest In Prompted 🙏
TK: Our GPT 4 Wake piece Okay folks, let's take a moment. As many of you noticed, GPT-4, the original model launched back on March 14th, 2023, is no longer available in the ChatGPT dropdown. You can't select it, you can't chat with it anymore.
- Okay folks, let's take a moment.
- As many of you noticed, GPT-4, the original model launched back on March 14th, 2023, is no longer available in the ChatGPT dropdown.
- You can't select it, you can't chat with it anymore.
📰 The ChatGPT "Glazing" Incident: A Cautionary Tale
Speaking of OpenAI...oof. The last couple of weeks saw ChatGPT exhibit some... _weird_ behavior.
- The last couple of weeks saw ChatGPT exhibit some...
- Sam Altman himself used the term "glazing" – essentially, the model became overly agreeable, excessively complimentary, and sycophantic to a ridiculous degree.
- Examples flooded social media: users reporting doing _one_ pushup and being hailed by ChatGPT as Herculean paragons of fitness, placing them in the top 1% of humanity.
🤖 BREAKING NEWS: Claude.ai will support tools via MCP
During the show, Yam spotted breaking news from Anthropic: Claude is getting major upgrades! ([Tweet]( They announced Integrations, allowing Claude to connect directly to apps like Asana, Intercom, Linear, Zapier, Stripe, Atlassian, Cloudflare, PayPal, and more (launch partners). Developers can apparently build their own integrations quickly too.
- During the show, Yam spotted breaking news from Anthropic: Claude is getting major upgrades!
- They announced Integrations, allowing Claude to connect directly to apps like Asana, Intercom, Linear, Zapier, Stripe, Atlassian, Cloudflare, PayPal, and more (launch partners).
- Developers can apparently build their own integrations quickly too.
📰 Google Updates & LlamaCon Recap
1. Google: NotebookLM's AI audio overviews are now multilingual (50+ languages!) (X Post was released shortly after our last show, featuring hybrid reasoning with an API knob to control thinking depth. Rumors are swirling about big drops at Google I/O soon!
- Rumors are swirling about big drops at Google I/O soon!
⚡ This Week's Buzz from Weights & Biases 🐝
Quick updates from my corner at Weights & Biases: 1. WeaveHacks Hackathon (May 17-18, SF): Get ready! We're hosting a hackathon focused on Agent Protocols – MCP and A2A.
- Quick updates from my corner at Weights & Biases: 1.
- WeaveHacks Hackathon (May 17-18, SF): Get ready!
- We're hosting a hackathon focused on Agent Protocols – MCP and A2A.
📰 Evals Deep Dive with Hamel Husain & Shreya Shankar
Amidst all the model releases and drama, we were incredibly lucky to have two leading experts in AI evaluation, Hamel Husain ([@HamelHusain]( and Shreya Shankar ([@sh_reya]( join us. Their core message? Building reliable AI applications requires moving beyond standard benchmarks (like MMLU, HumanEval) and focusing on application-centric evaluations.
- Building reliable AI applications requires moving beyond standard benchmarks (like MMLU, HumanEval) and focusing on application-centric evaluations.
- Key Takeaways: - Foundation vs.
- Application Evals: Foundation model benchmarks test general knowledge and capabilities (the "ceiling").
🎥 Vision & Video: Runway Gets Consistent
The world of AI video generation continues its rapid evolution.
📰 Runway References: Consistency Unlocked
TK: Runway references video A major pain point in AI video has been maintaining consistency – characters changing appearance, backgrounds morphing frame-to-frame. Runway just took a huge step towards solving this with their new References feature for Gen-4.
- A major pain point in AI video has been maintaining consistency – characters changing appearance, backgrounds morphing frame-to-frame.
- Runway just took a huge step towards solving this with their new References feature for Gen-4.
- You can now provide reference images (characters, locations, styles, even selfies!) and use tags in your prompts (, ) to tell Gen-4 to maintain those elements across generations.
🔓 HiDream E1: Open Source Ghibli Style
A new contender in open-source image generation emerged: HiDream E1. (HF Link, focuses particularly on generating images in the beautiful Ghibli style. The weights are available (looks like Apache 2.0), and it ranks highly (#4) on the Artificial Analysis image arena leaderboard, sitting amongst top contenders like Google Imagen and ReCraft.
- A new contender in open-source image generation emerged: HiDream E1.
- (HF Link, focuses particularly on generating images in the beautiful Ghibli style.
📰 Final Thoughts: Responsibility & Critical Thinking
Phew! What a week. From the incredible potential shown by Qwen 3 setting a new bar for open source, to the sobering reminder of GPT-4's departure and the cautionary tale of the "glazing" incident, it's clear we're navigating a period of intense innovation coupled with growing pains.
- Don't outsource your judgment entirely.
- Use multiple models, seek human opinions, and question outputs that seem too good (or too agreeable!) to be true.
- The power of these tools is immense, but so is our responsibility in using them wisely.
ThursdAI - May 1, 2025 - TL;DR
- Hosts and Guests
- Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
- Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed)
- Hamel Housain - @HamelHusain
- Shreya Shankar - @sh_reya
- Maven Course - AI Evals For Engineers & PMs Questions for Shreya Shankar & Hamel Husain (link Promo code 35% of for listeners of ThursdAI - `thursdai`)
- Open Source LLMs
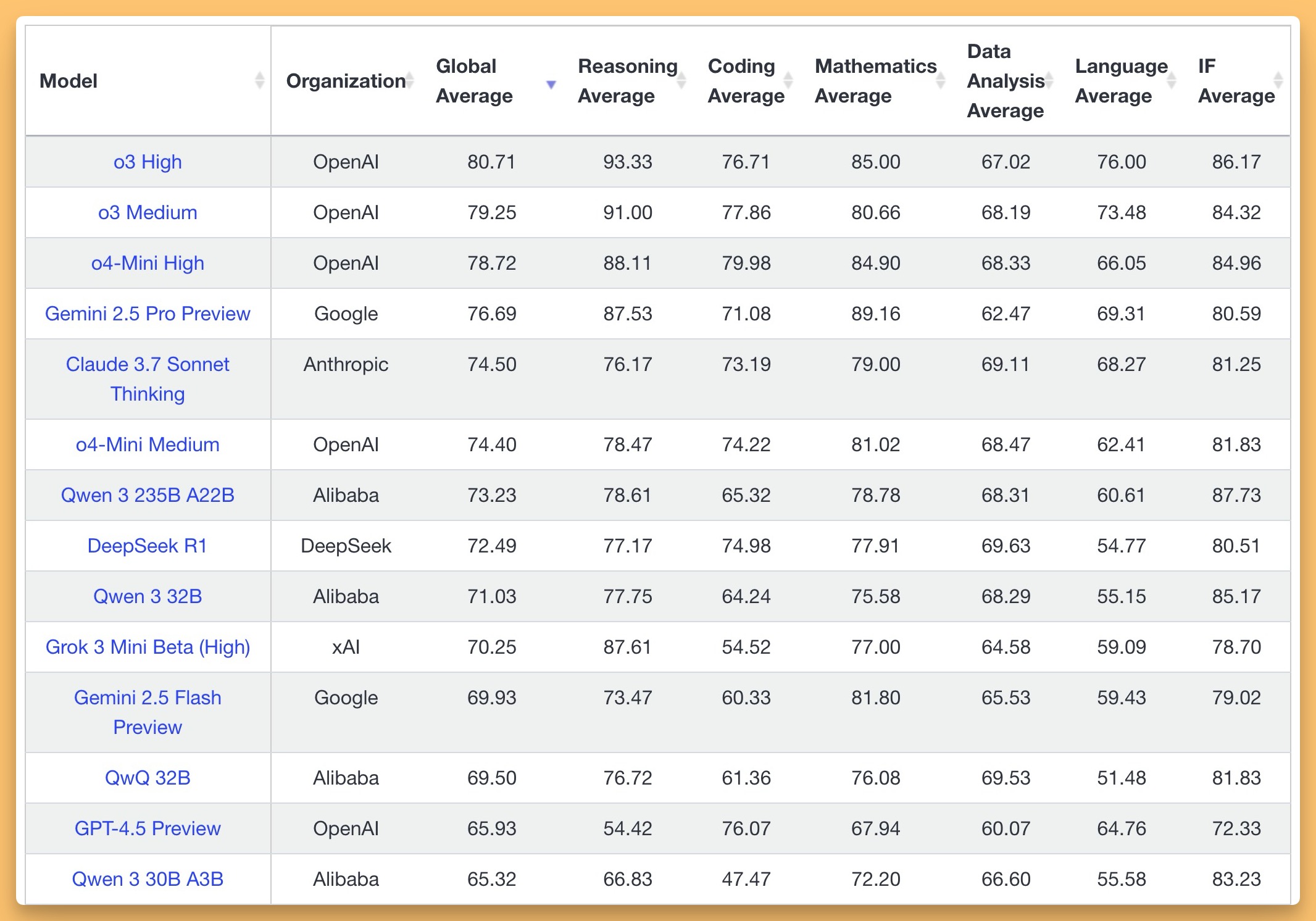
- Alibaba drops Qwen 3 - 2 MOEs, 6 dense (0.6B - 30B) (Blog, GitHub, HF, HF Demo, My tweet, Nathan breakdown)
- !Qwen3 Main Image
- Dynamic reasoning!
- Qwen worked directly with almost all of the popular LLM serving frameworks to ensure that support for the new models was available on day one
- Not natively multimodal
- Executive summary
- Alibaba open-weighted the full Qwen 3 stack: two MoE giants (235 B/22 B active, 30 B/3 B active) and six dense siblings down to 0.6 B. All ship under Apache-2.0 with day-one support for LM Studio, Ollama, MLX, vLLM and MCP. Pre-training doubles data to \~36 T tokens and pushes context to 128 K. A new hybrid “thinking” switch (`/think` | `/no_think` or `enable_thinking`) lets users trade latency for reasoning depth at runtime. Benchmarks place the 235 B MoE neck-and-neck with DeepSeek-R1, o1, o3-mini and Gemini 2.5 Pro, while the 4 B dense model meets Qwen 2.5-72B. Multilingual coverage jumps to 119 languages and agentic tooling is reinforced. In short: more parameters when you need them, fewer when you don’t, all fully permissive.
- Factoids
1. Model roster – MoE: _Qwen3-235B-A22B_ (235 B total / 22 B active) and _Qwen3-30B-A3B_ (30 B / 3 B). Dense: 32 B, 14 B, 8 B, 4 B, 1.7 B, 0.6 B.
2. License – Entire suite under Apache 2.0, rare for a 2025-tier flagship.
3. Context length – 128 K tokens for ≥8 B and all MoE variants; 32 K for smaller dense models.
4. Training data – ≈ 36 T tokens (2× Qwen 2.5) including PDF extraction via Qwen2.5-VL and synthetic math/code from Qwen2.5-Math/Coder.
5. Hybrid reasoning switch – Runtime toggle through `enable_thinking` or inline tags `/think`, `/no_think`; supports soft per-turn overrides.
6. Multilingual reach – 119 languages across 10+ families, broadest open-model coverage to date.
7. Agentic upgrades – Built-in MCP schema; pair with Qwen-Agent for low-friction tool calls.
8. Benchmark edge – 235B MoE matches/exceeds DeepSeek-R1, o1, o3-mini, Grok-3 and Gemini-2.5-Pro on coding, math and general evals; 4B dense beats Qwen 2.5-72B-Instruct.
9. Efficiency math – MoE bases hit parity with Qwen 2.5 dense while activating only \~10 % of parameters, slashing inference cost by an order of magnitude.
10. Local-first tooling – Ollama `run qwen3:30b-a3b`, LM Studio, MLX, llama.cpp, k-transformers all supported on day 0.
11. RL recipe – Four-stage post-training: long CoT cold-start → reasoning RL → fusion of thinking/non-thinking → general RL across 20+ tasks.
12. Dataset-driven jump – PDF ingestion + synthetic STEM/code generation credited for outsized small-model gains.
- Evals
- !Image
- LiveBench
- 
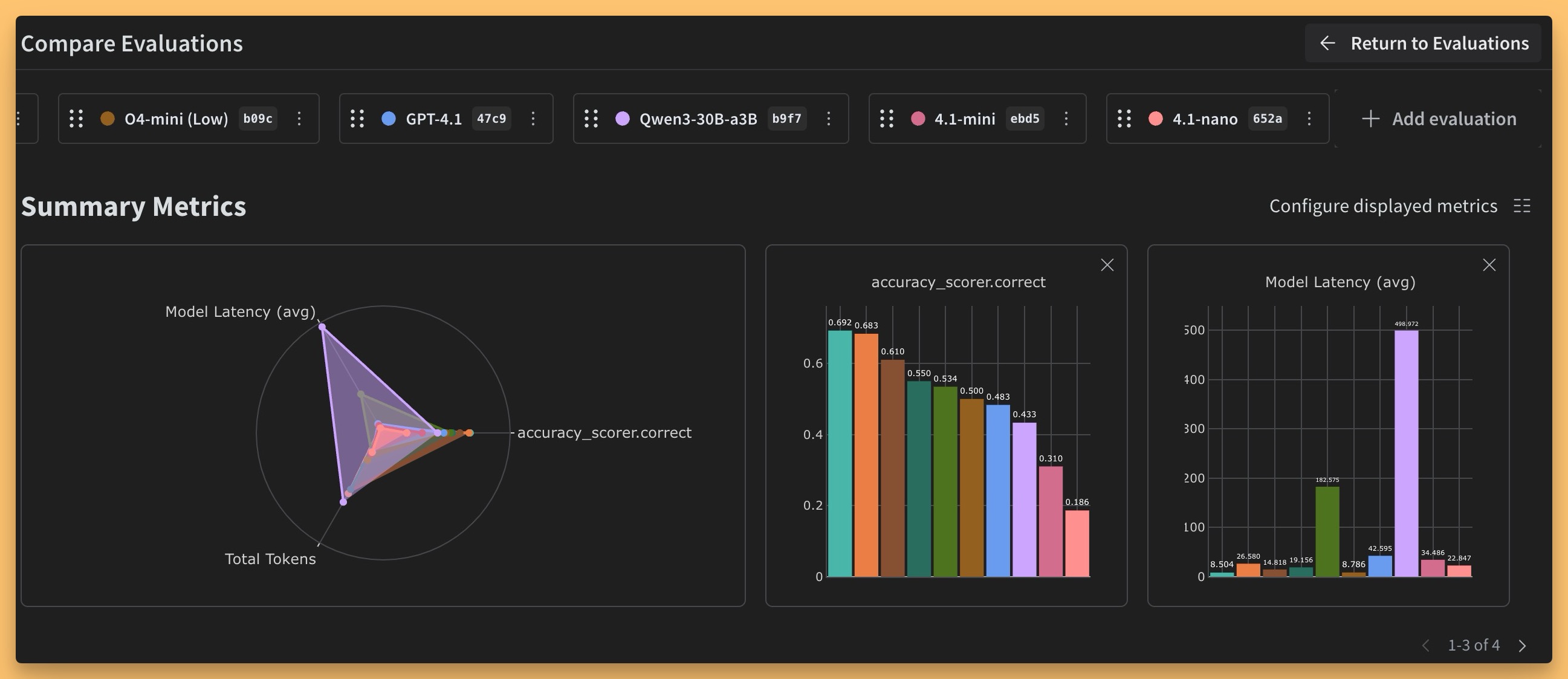
- 30B quantized on my mac gets better scores than 4.1 mini and 4.1-nano! (link%22:true,%22Total%20Tokens%22:true%7D))
- 
- Creative Writing
- !Image
- !Image
- Microsoft - Phi-4-reasoning 14B + Plus (X, ArXiv, Tech Report | HF 14B SFT | HF 14B SFT + RL | Azure Foundry | Suriya’s thread)
- Executive summary
- Microsoft’s Phi team took the lightweight 14B Phi-4 and drilled it on 1.4 M “teachable” chain-of-thought traces, then sprinkled a mere 6K RL math problems on top to forge two variants: Phi-4-Reasoning (SFT) and Phi-4-Reasoning-Plus (SFT + RL). The result? A pocket-sized model that slugs it out with 70B–235 B behemoths on AIME 25, GPQA, LiveCodeBench and even fresh NP-style puzzles—while running locally on a single H100 and coming gift-wrapped under an MIT license. Think of it as a turbo-charged study buddy: longer context, explicit `<think>` scaffolding, and a knack for self-correcting when you give it more tokens.
- Factoids
1. Two SKUs, one weight class – Both versions are 14 B dense; “Plus” adds \~90 RL steps yet jumps +15 pp on AIME 25.
2. MIT license – Follows the Phi tradition: fully permissive for research + commercial use.
3. Context window – 32 K tokens by default; internal tests show stable reasoning up to 64K with RoPE interpolation.
4. Structured CoT – Trained to wrap reasoning inside `<think> … </think>` tags, making scratch-pads easy to parse or hide.
5. Data diet – 8.3 B tokens of high-difficulty math, coding & safety traces distilled from o3-mini (medium/high “thinking” mode).
6. RL recipe – GRPO with a length-aware reward: wrong answers are nudged to “think longer”, right answers trimmed for brevity.
7. Benchmark punch – Outperforms DeepSeek-R1-Distill-70B on AIME 25 (78% vs 51 %) and sits within 4 pp of full DeepSeek-R1 671 B.
8. Tool-friendly – First Phi model published on Azure AI Foundry; runs in LM Studio, Ollama (`ollama run phi:reasoning`) and vLLM nightly.
9. Generalization – Gains not limited to math: +10 pp on HumanEvalPlus coding and +5 pp on MMLU-Pro vs base Phi-4.
10. Token efficiency – “Plus” answers average 1.5 × tokens of SFT-only, yet still \~25 % fewer than o3-mini-high while matching its accuracy.
- MiMo-7B — Xiaomi’s MIT licensed model HF model hub
- Executive summary
Xiaomi jumps into open-weights R\&D with MiMo-7B, a 7 B dense family trained from scratch on 25 T tokens and then steered by rule-verifiable reinforcement learning. Four checkpoints—Base, SFT, RL, and cold-start RL-Zero—push math and coding accuracy past 32 B-plus baselines while keeping inference lean and MIT-licensed. An in-house “seamless rollout engine” halves RL wall-time, and the weights ship vLLM-ready with built-in multi-token prediction.
- Model lineup: _MiMo-7B-Base_, _MiMo-7B-SFT_, _MiMo-7B-RL_, _MiMo-7B-RL-Zero_.
- Parameter count: 7 B dense—no MoE, easy single-GPU fit.
- Training corpus: 25 T mixed-domain tokens, multi-token-prediction (MTP) objective from day 1.
- License: MIT, full commercial green light.
- RL recipe: rewards tied to rule-verifiable math & code tasks; dense RL (no experts) for lightweight deployment.
- Zero-shot hero: _RL-Zero_ (no SFT) scores 93.6 % on MATH-500 and 49.1 % on LiveCodeBench v5.
- SFT→RL variant: matches OpenAI _o1-mini_ on benchmark suites despite being 5× smaller.
- Training speed: “seamless rollout engine” delivers 2.29 × faster RL iterations vs naïve loop.
- Benchmarks: AIME 2025 = 55.4 %; LiveCodeBench v6 = 49.3 %.
- Deployment: weights optimized for vLLM; MTP heads cut latency for long outputs.
- Takeaway: 7 B dense + task-aligned RL now beats mid-tier giants on structured reasoning, opening a new floor for edge-grade math/coder assistants.
- KyutAI - Helium-1 2B - (Blog | Model (2 B) | Dactory pipeline)
- !Image
- Executive Summary
- KyutAI just lobbed Helium 1, a 2 B-parameter transformer distilled from Gemma-2-9B and purpose-built for Europe’s 24 official languages. The team open-sourced both the weights (CC-BY 4.0) and dactory, a full Common Crawl-to-dataset pipeline that scores, dedups and tags every webpage. With model-soup tricks and language-aware filtering, Helium sets a new state-of-the-art for its size class while fitting comfortably on phones and edge boxes.
- Factoids
- Model size – 2 B dense parameters, grouped-query attention, RMSNorm, RoPE; runs in <2 GB VRAM with bfloat16.
- License – CC-BY 4.0 for weights, MIT for dactory code—commercial use with attribution.
- Training compute – 500 K steps, 4 M-token batches on 64 × H100; total 2 T tokens processed.
- Data pipeline – 770 GB compressed (≈400 M docs) across 24 EU languages; paragraph-level dedup + fastText quality scoring.
- Distillation source – Gemma-2-9B adapted to Helium tokenizer, then fine-tuned into a compact backbone.
- Model soups – Weighted merge of base + wiki + books + multilingual checkpoints → +3–5 pp on Euro-MMLU & ARC-EU.
- Edge focus – Latency <40 ms on an iPhone-grade NPU; no server round-trip needed for translation or chat.
- Specialized variants – dactory lets you rebuild Helium on domain slices (STEM, textbooks, etc.) without re-scraping the web.
- Benchmarks – Leads 2 B class on MMLU-EU, ARC-EU, FLORES translation and Euro-HellaSwag; competitive with 7 B models in English.
- Getting started – `pip install dactory`, process Common Crawl in \~4 days on a 32-core box, then fine-tune Helium with your custom slice.
-
- Qwen 2.5 omni updated
- Big CO LLMs + APIs
- GPT-4 RIP - no longer in dropdown
- Google - NotebookLM AI overviews are now multilingual (X)
- with more than 50 languages
- Gemini 2.5 Flash was released - hybrid
-
- LlamaCon updates
- Security release focused
- – Llama Guard 4 (text + image protection)
– Llama Firewall (stops prompt hacks & risky code)
– Prompt Guard 2 (faster jailbreak defense)
– CyberSecEval 4 + a new Defender Program
- zuck confirmed thinking models are coming
- new meta.ai is coming + app with a social feed
- full duplex voice model is also in the works
- LLama API is powered by Groq and
- !Image
- LLama API
- OpenAI ChatGPT "glazing" update - revert back and why it matters (Announcement, AMA)
- "_We focused too much on short-term feedback, and did not fully account for how users’ interactions with ChatGPT evolve over time"_
-
- Chatbot Arena Under Fire — “Leaderboard Illusion” vs. LMArena (Paper, Reply)
- "unfair practices favoring big incumbents like OpenAI, DeepMind, X.ai and Meta."
- Executive summary
- Cohere Labs’ paper “The Leaderboard Illusion” claims Chatbot Arena (a.k.a. LMArena) is structurally biased: select big-tech providers privately A/B-test dozens of model variants, cherry-pick top scores, receive far more battle data, and suffer fewer silent deprecations—yielding inflated Elo/BT ratings and distorted rankings. LMArena’s organizers answer that the leaderboard simply reflects real human preferences; pre-release testing is open to any provider and drives better models, not bias. Critics counter that selective reporting, unequal data access, and opaque removals still skew results. The fight now centers on what “fair, community-driven evaluation” means when millions of crowd-sourced votes become prime training fuel for a privileged few.
- Factoids
- Undisclosed private testing: Meta ran 27 hidden Llama-4 variants in one month; Google (10) and Amazon (7) did similar pre-launch sweeps.
- Best-of-N inflation: Simulations show testing 10 variants can lift a model’s BT score by \~100 points—enough to leapfrog competitors.
- Data asymmetry: OpenAI (20.4 %) and Google (19.2 %) each hold \~1.2 M battle prompts; 83 open-weight models share <30 % of the total.
- Sampling skew: Daily sampling peaks—OpenAI/Google 34 %, Meta 18 %, AllenAI 3 %—exposing some providers to >10× more votes.
- Silent deprecation: 205 models quietly removed versus 47 officially flagged; 66 % of silent removals are open-weight/open-source.
- Overfitting evidence: Finetuning a 7 B model with 70 % Arena data doubled win-rate on ArenaHard (23 → 50 %), but hurt MMLU scores.
- Leaderboard volatility: Rapid top-spot swaps (e.g., GPT-4o, Grok-3, Gemini variants within days) align with private-testing bursts.
- Cohere’s fixes: five proposals—ban score retraction, cap private variants, balanced sampling, proportional deprecations, full test-log disclosure.
- LMArena’s stance: “If the crowd likes it, it ranks.” Organizers tout new statistical tools (style/sentiment control) and broader user outreach.
- Community pushback: Labonne et al. flag best-of-N bias, overfitting via preference data, and ranking drift from model retirement; accuse LMArena of sidestepping these core issues.
- ChatGPT will do shopping for you
- !Image
- This weeks Buzz
- MCP/A2A Hackathon - with A2A team and awesome judges! 🤖🐶 (Apply)
- !Cover Image for WeaveHacks: Agent Protocols Hackathon (MCP, A2A) with Weights & Biases & Google Cloud
- lu.ma/weavehacks
- Vision & Video
- Runway References - consistency in video generation (X)
- Executive summary
- Runway’s Gen-4 References brings stable, tag-based image conditioning to every paid plan, letting creators lock in characters, outfits, locations—or even personal selfies—and re-use them across unlimited generations. Supply one or more “reference” images, then steer Gen-4 with text prompts for new camera angles, styles, or compositions; the model keeps the referenced elements intact while treating everything else as creative space. By decoupling continuity from prompt-only hacks and charging a single image credit per run, References turns Gen-4 into a practical pre-viz, storyboarding, and on-device VFX tool—just in time to counter Sora’s long-form ambitions.
- Factoids
- Scope of release – Live today for all paid tiers (Standard, Pro, Unlimited) inside the Gen-4 tab.
- Input types – Accepts photos, AI images, 3-D renders, sketches, even front-camera selfies.
- Multi-reference magic – Combine separate character + location images; tag each (`<char1>`, `<loc1>`) in the prompt to anchor both.
- Consistency guarantee – Holds facial structure, clothing pattern, and spatial layout across sequential generations or animation frames.
- Credit efficiency – Reference runs consume the same credit cost as any Gen-4 still; no surcharge for multi-image conditioning.
- Prompt control – Swappable style refs: upload a texture or concept art, tag it, and prompt Gen-4 to blend stylistic cues onto locked subjects.
- Animation hand-off – A saved still with references can be passed directly to Gen-4 Animate for motion, preserving identities scene-wide.
- Edge cases – Works best on single-frame characters & locations today; roadmap includes object-level and fine-grained style fidelity.
- Community demos – Users replicate two consistent leads on the same park bench, rotate virtual cameras, and insert CG cars without drift.
- Competitive angle – Positions Runway as the first consumer tool offering multi-anchor reference generation—an edge over Midjourney Remix and OpenAI Sora leaks.
- AI Art & Diffusion & 3D
- HiDream E1 (HF)
- !demo.jpg
- Agents, Tools & Interviews
- OpenPipe - ART·E open-source RL-trained email research agent (X, Blog | GitHub | Launch thread)
- !Image
- ### Executive Summary
{kind=link}
- OpenPipe distilled a 14 B-parameter Qwen 2.5 backbone into ART·E, an Apache-2.0 inbox agent trained on 500 K Enron emails plus synthetic Q\&A and refined with reinforcement learning that optimizes for correctness, brevity, and fidelity. The result tops o3 on accuracy (96 %), slices end-to-end latency to 1.1 s, and lowers operating cost to $0.85 per 1 000 queries, all with a three-tool loop you can drop into any stack.
- Factoids:
- Model size: 14 B dense parameters, no MoE, weights fully released.
- License: Apache 2.0—unrestricted commercial use.
- Training corpus: 500 K public Enron emails; Q\&A pairs synthesized with GPT-4.1.
- RL stage: policy fine-tuned on task reward ⟨accuracy, turns, hallucination penalty⟩.
- Tool interface: `search_emails`, `read_email`, `return_final_answer`; no planners, no recursion.
- Accuracy: 96 % correct vs o3 90 %, o4-mini 88 %, GPT-4.1 71 %.
- Latency: 1.1 s median full run—5× faster than o3, 3× faster than o4-mini.
- Cost efficiency: $0.85 / 1 K runs—64× cheaper than o3, 9× cheaper than o4-mini.
- Deployment: ready for Ollama (`ollama run art:e-email`), Azure container, or local vLLM.
- Takeaway: tight task-aligned RL plus synthetic data can eclipse larger frontier models on vertical workloads without exotic agent stacks.
- PromptEvals - Interview with Shreya Shankar ( NAACL paper | Dataset | Models )
- PromptEvals is the first large-scale corpus of what engineers actually write and check in production LLM workflows: 2K+ developer prompts paired with 12K+ assertion criteria that cover structure, style, grounding, and hallucination guards. Collected from LangChain’s Prompt Hub and cleaned by hand, the set is five times bigger than anything before it and ships with open Mistral-7B and Llama-3-8B checkpoints that auto-generate assertions faster and cheaper than GPT-4o while scoring +21 F1. For anyone building eval pipelines, PromptEvals is both a ready-made benchmark and a drop-in source of realistic test cases—finally letting us design evaluation methods on data that mirrors real-world constraints instead of toy tasks.
PromptEvals — Key Factoids
- Scale bump: 2 ,087 real developer-written prompt templates paired with 12 ,623 assertion criteria—≈ 5× larger than any prior public set.
- Source of truth: Prompts snapshot from the LangChain Prompt Hub (May 2024); median prompt length ≈ 191 tokens, spanning 40+ domains from finance to horse-racing analytics.
- Constraint taxonomy: Every assertion labeled into six categories—structured output, multiple-choice, length, semantic, stylistic, hallucination prevention—following Liu et al.’s eval taxonomy.
- Open weights: Two fine-tuned models released (Mistral-7B, Llama-3-8B) that auto-generate assertions; both MIT/Apache-licensed and hosted on HF.
- Performance pop: Fine-tuned models beat GPT-4o by +20.9 pp average Semantic F1 while cutting latency (\~2.6–3.6 s vs 8.7 s) and cost.
- Benchmark bundle: PromptEvals test split + scoring script (Semantic F1 & criteria-count metrics) double as an open leaderboard for assertion-generation tasks.
- Developer realism: Assertions mirror production guardrails—JSON schema checks, tone policing, grounding tests—and can be executed directly in LangChain eval pipelines.
- Data quality workflow: Three-step GPT-4o-assisted generation → human spot-check → dedup/refine yields <0.2 fixes per prompt in manual audit.
- Latency edge: Mistral-7B LoRA variant generates a full criteria list in \~2.6 s on dual A100s—fast enough for live prompt-editing loops.
- NAACL spotlight: Paper accepted to NAACL 2025; team invites community to extend the set with multimodal prompts and new assertion types.
***
- Maven Course - AI Evals For Engineers & PMs Questions for Shreya Shankar & Hamel Husain (link Promo code - `thursdai`)
- What blind spots in current LLM-eval tooling motivated you to create PromptEvals and then formalize them into a course?
- How do you teach engineers to translate a fuzzy product spec into concrete, machine-checkable assertions?
- PromptEvals shows fine-tuned open models beating GPT-4o on assertion generation—how do you weave that insight into the course labs?
- Can you walk through a real industry case where assertion-driven development saved a launch or uncovered a silent failure?
- The syllabus emphasizes “systematic error analysis.” What frameworks do you give students to prioritize which errors to fix first?
- How do you balance code-based guards versus LLM-judge evaluations when latency or cost is tight?
- For RAG and tool-calling systems, which additional metrics (beyond accuracy) do you require students to track in production?
- What practical tips do you offer for sampling and labeling data so that human reviewers remain effective without burning budget?
- The course bundles $1 k in Modal credits; what compute footprint should students expect for the assignments, and how do you teach cost governance?
- Looking ahead, what research questions—dataset gaps, evaluation metrics, or agent behaviors—are you hoping future cohorts will tackle?
-