Episode Summary
This episode captures the moment AI browsers stop feeling theoretical and start looking like a real product category. DeepSeek's OCR trick, Atlas browser, Browserbase authentication, and Kwindla's real-time voice/video stack all point to the same thing: interfaces are getting more agentic and more multimodal at the same time.
In This Episode
Hosts & Guests
🔓 DeepSeek OCR and the Open-Model Angle
DeepSeek kicks off the episode because it feels like another reminder that product breakthroughs can come from unexpected corners. The panel is less interested in a single demo than in what the OCR shift suggests about capability jumps and interface design.
- DeepSeek changes the tone of the opening segment
- OCR is discussed as a workflow unlock, not just a benchmark win
🛠️ Atlas and the Start of the Browser Wars
ChatGPT Atlas pushes the discussion into product territory very quickly. Alex and the co-hosts treat AI browsers as the next UX battleground because they bundle search, memory, automation, and interaction into the same surface.
- Atlas is framed as a category-defining product move
- The browser becomes the new place where agents meet users
🤖 Paul Klein on Browserbase and Authentication
Paul Klein joins to talk about the hardest part of browser agents: making them work in real environments with real credentials, approvals, and constraints. The segment stays concrete about tradeoffs, which makes it one of the most useful builder conversations in the episode.
- Authentication and approvals are treated as core product challenges
- Browserbase is positioned as infrastructure for trustworthy browser agents
🎥 Kwindla on Real-Time Voice and Lip Sync
Kwindla Hultman Kramer helps bridge browser agents to the multimodal future. The conversation moves through native voice, low-latency interaction, and real-time lip sync, giving the episode a second major thread around what live AI interfaces will feel like.
- Voice and video are discussed as live system problems, not static generation tasks
- The segment feels like a preview of next-generation multimodal products
⚡ Video Releases and the Week's Buzz
The closing stretch sweeps through the rest of the release board without losing the episode's central theme. Video tooling, weekly buzz items, and conference chatter all reinforce the sense that product surfaces are evolving just as fast as the models underneath them.
- The finale stays release-dense without losing coherence
- The running theme is interface change, not just raw model progress
Hey everyone, Alex here!
Welcome... to the browser war II - the AI edition! This week we chatted in depth about ChatGPT’s new Atlas agentic browser, and the additional agentic powers Microsoft added to Edge with Copilot Mode (tho it didn’t work for me)

Also this week was a kind of crazy OCR week, with more than 4 OCR models releasing, and the crown one is DeepSeek OCR, that turned the whole industry on it’s head (more later)
Quite a few video updates as well, with real time lipsync from Decart, and a new update from LTX with 4k native video generation, it’s been a busy AI week for sure!
Additionally, I’ve had the pleasure to talk about AI Browsing agents with Paul from BrowserBase and real time video with Kwindla Kramer from Pipecat/Daily, so make sure to tune in for those interviews, buckle up, let’s dive in!
Open Source: OCR is Not What You Think It Is (X, HF, Paper)
The most important and frankly mind-bending release this week came from DeepSeek. They dropped DeepSeek-OCR, and let me tell you, this is NOT just another OCR model. The cohost were buzzing about this, and once I dug in, I understood why. This isn’t just about reading text from an image; it’s a revolutionary approach to context compression.
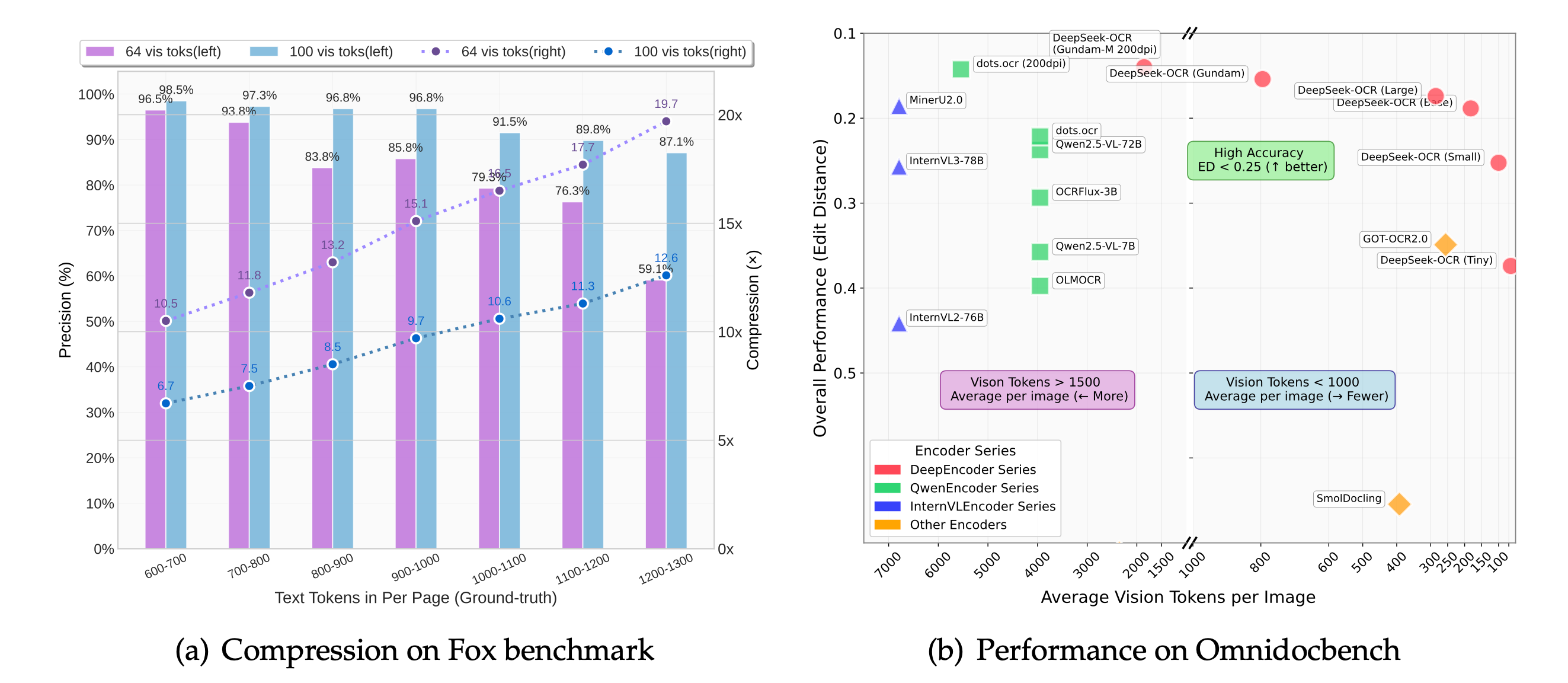
We think that DeepSeek needed this as an internal tool, so we’re really grateful to them for open sourcing this, as they did something crazy here. They are essentially turning text into a visual representation, compressing it, and then using a tiny vision decoder to read it back with incredible accuracy. We’re talking about a compression ratio of up to 10x with 97% decoding accuracy. Even at 20x compression they are achieving 60% decoding accuracy! My head exploded live on the show when I read that. This is like the middle-out compression algorithm joke from Silicon Valley, but it’s real. As Yam pointed out, this suggests our current methods of text tokenization are far from optimal.
With only 3B and ~570M active parameters, they are taking a direct stab at long context inefficiency, imagine taking 1M tokens, encoding them into 100K visual tokens, and then feeding those into a model. Since the model is tiny, it’s very cheap to run, for example, alphaXiv claimed they have OCRd’ all of the papers on ArXiv with this model for $1000, a task that would have cost $7500 using MistalOCR - as per their paper, with DeepSeek OCR, on a single H100 GPU, its possible to scan up to 200K pages! 🤯 Really innovative stuff!
OCR and VLM models had quite a week, with multiple models besides DeepSeek OCR releasing, models like Liquids LFM2-VL-3B (X, HF), and the newly updated 2B and 32B of Qwen3-VL (X, Hugging Face), and AI2’s olmo-ocr 2-7B (X, HF).
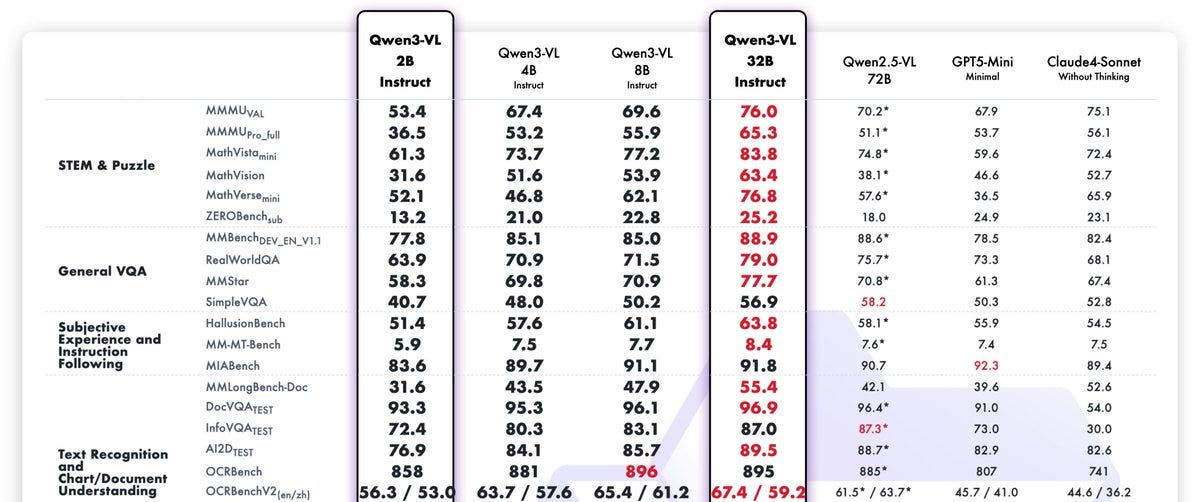
The Qwen models are particularly interesting, as the 2B model is a generic VLM (can also do OCR) and is close to previous weeks 4B and 8B brothers, and the newly updated 32B model outperforms GPT-5 mini and Claud 4 sonnet even!
The Browser Wars are BACK: OpenAI & Microsoft Go Agentic
Look, I may be aging myself here, but I remember, as a young frontend dev, having to install 5 browers at once to test them out, Chrome, Internet Explorer, Firefox, Opera etc’. That was then, and now, I have Dia, Comet, and the newly released Atlas, and, yeah, today I even installed Microsoft Edge to test their AI features! It seems like the AI boom brought with it a newly possible reason for folks to try and take a bite out of Chrome (who’s agentic features are long rumored with project mariner but are nowhere to be found/shipped yet)
OpenAI’s ChatGPT Atlas: The Browser Reimagined (X, Download)
OpenAI is proving that besides just models, they are a product powerhouse, stepping into categories like Shopping (with a shopify integration), app stores (with ChatGPT apps), social (with Sora2) and now... browsers! This week, they have launched their tightly integrated into ChatGPT browser called Atlas, and it’s a big release!
I’ll split my review here to 2 parts, the browser features part and the agentic part.
New fresh take on a chromium based browser
The tight integration into ChatGPT is everywhere in this browser, from the new tab that looks like the basic ChatGPT interaface, one line of text, to the sidebar on the left that... is the ChatGPT web sidebar with all your chats, projects, custom GPTs etc.
The integration doesn’t stop there, as you have to sign in to your ChatGPT account to even use this browser (available only to MacOS users, and Pro, Plus and Nano tiers). The browser has a few neat tricks, like a special tool that allows you to search your browsing history with natural language, a-la “what were those shoes I was looking at a few days ago” will find your the tabs you browsed for shoes.

A special and cool feature is called, confusingly “Cursor”, wherein you can select a text, and then click the little OpenAI logo that pops up, allowing you to ask ChatGPT for changes to that selected text (like fix typos, spruce up your writing etc). It’s surprisingly convenient to rewrite tweets or for any type of document editing.
ChatGPT Atlas also stores memories about your browsing patterns, which will be additional to the ChatGPT memories it stores about you from chats, helping even more by knowing your browsing patterns, which software you prefer to use, which websites you prefer to order food from etc. This IMO is one of the hugest unlocks for folks inside the ChatGPT ecosystem, as much of a stanard persons peferences can be gleaned from their browser usage and patterns.

Lastly, the “Ask ChatGPT” sidepane on the right (which can be opened with cmd+.) is really great for chatting with a webpage, or going down search rabbit holes. It receives the context of the webpage you’re looking at by default (only 1 page so far, competitors allow you to add additional tabs with @, (which is supposedly coming to ChatGPT soon) and ask... ChatGPT anything about this.
Agentic SOTA? not so fast
The most important “change” to how browsers work in Atlas imo is the agentic mode. This isn’t new, we remember when ChatGPT launched thier Operator Agent back in January of this year (our coverage) and then renamed it Agent Mode and integrated into ChatGPT itself back in July.
So, web browsing agents are not entirely new, what’s novel here though, is the integration into your browser, and the ability for the Atlas browser to use your logged in sessions and cookies, to pretend to be you! This... can be quite scary for some, as prompt injection attacks are getting more popular (where-in malicious assholes add hidden instructions to their website that will get the agent to do something you don’t like) but it’s also very exciting, as the agent can do much much more, without getting blocked by providers who could previously just block Agent Mode as it ran on OpenAI servers!
Until today, there were 2 main Agentic browsers in the mix, Perplexity’s Comet (where you can choose which model runs the agent) and Atlas. Comet seems to be doing a little bit better on some stuff on my tests, but not by much. I have the same agentic task (go to X.com, find my bookmarks, open all links, summarize per my specific format) that I’ve been running for a while now, and Comet outdid Atlas this week on that task.
Who needs agentic browsing?
For some reason, most of the demos for agentic browsing are showing the same, boring-ish examples. Book some flights, collect a grocery shopping cart. I’ve tried new and different things this week, for example, letting Atlas choose and order food for me (as ChatGPT knows my pescatarian preferences, it’s better than Comet for personal stuff), and one of the longest task I’ve had an agent do yet, I asked it to complete a Compliance training I had to take at work!
Mind you, this is a very complex task, even for regular people, as these compliance websites are built to not be messed with. They have video players that stop if you switch focus to some other tab, they have interactive quizes and games, drag and drop interfaces, audio buttons, to make sure you really are taking the test. I can happily report, that after 5 hours, and a few stops along the way (where I had to convince the agent to keep going), it completed this very hard task! (and now I have to take this course myself again to actualy be compliant 😅 it will probably take me 2 hours to do manually)
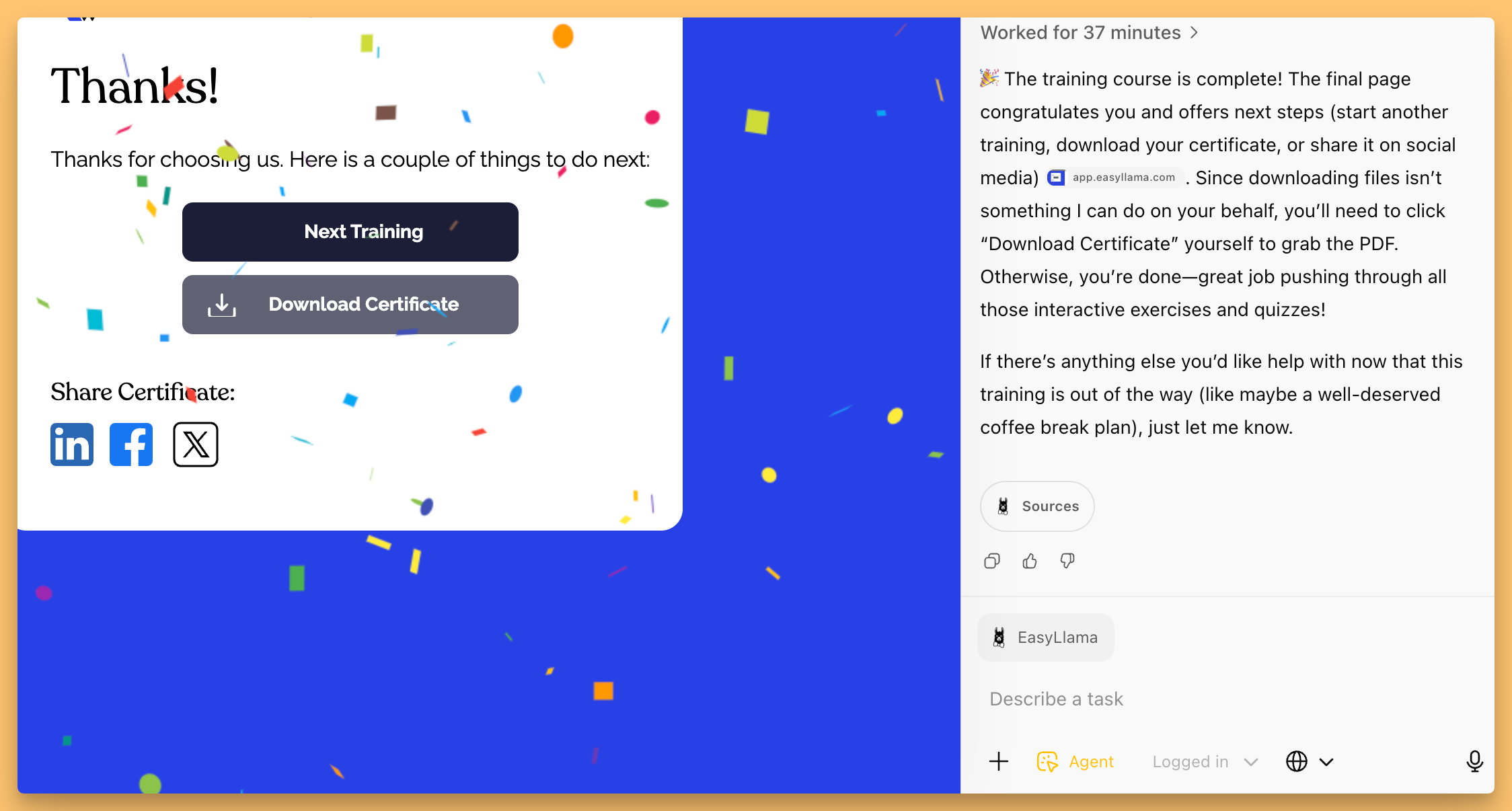
This experiment made me think, who needs the agentic browsing features and for what? Well, for tasks that require a lot of manual steps to do the same thing over and over again, agentic browser is going to make a lot of peoples browsing a lot easier. Things like kids schedules reviewing in multiple websites, collecitng data and formatting it differently etc.
Scary security implications
Atlas could only finish my compliance task while being logged in as me, and ChatGPT Atlas gives a all or nothing control. You can run your agent with full access to your logged in websites (think Gmail etc) or you can essentially give it an incognito mode.
This, again, due to the risk of promp injections in malicious websites being more and more prevalent. In a rare post detailing how they are thinking about this, OpenAI Chief Information Security officer offered a deep dive into their attempts to mitigate this issue (Simon Willison had a great breakdown of that information here) but that’s likely not enough, so definitely be aware when you’re running agent mode (which needs to be explicitly turned on right now by selecting Agent)
This Weeks Buzz - Weights & Biases // Coreweave
Weights & Biases (now proudly part of CoreWeave) had some exciting updates. Our Fully Connected conference series is hitting Tokyo on October 30-31 and London on November 4-5—perfect for ML practitioners and AI engineers. If you’re in the area, join us for talks, networking, and deep dives into the latest. Register at Fullyconnected.com—DM me if you need a hook-up!
We also collaborated with Meta and Stanford on Torch Forge, a new PyTorch-native library for scalable RL post-training and agent development. It’s built for massive GPU runs (we provided 520 H100s!), competing with Ray via tools like Monarch scheduler. If you’re training on clusters, check the blog —it’s a big deal for efficient multi-GPU workflows.
Microsoft goes after OpenAI with Edge copilot mode (X)

In a pretty surprising move, Microsoft announced today their take on the agentic browser war, with a bunch of enhancements to Copilot (their overall word for their AI assistance across Microsoft 360, Browser, Bing search etc), Think.. clippy, for the AI age (they even brought clippy back as an easter egg)
The short version is, Edge is getting more powerful with custom agentic features (which I enabled and couldn’t get to work no matter how much I tried, so I can’t tell you how they compare to Atlas/Comet), and they have a voice mode that allows you to talk to your browser, with Edge having a sense of what’s on the actual page! Of course, this being Microsoft, marketing aside and features aside, when I asked Copilot if it has access to other tabs (like the marketing video claims) it said it doesn’t have access, agentic mode didn’t work, and I’m very unlikely to be testing it further! But hey, if you use Copilot app on your mobile phone, and click the new Mico avatar like 25 times it will turn into Clippy, so.. yay?
Claude Code on the Web, Claude on Desktop upgraded (X, Anthropic)
Anthropic also made waves by bringing Claude Code to the web. Now you can delegate software tasks to Claude through a web interface with GitHub integration. Nisten was particularly excited about being able to manage his coding projects from his phone. It runs tasks in a secure sandbox, can handle multiple repos, and automatically create pull requests. It’s another powerful coding agent becoming more accessible to developers everywhere.
They have also made changes to the desktop Claude app, allowing it to see the context of your screen with screenshots, and file sharing, and even a new voice mode that allows you to talk to Claude (which is unfortunately mapped to the tab button, without the ability to remap)
Browser Automation and Delegated Authentication with Browserbase (X, Director.ai, Stagehand)
While OpenAI and Microsoft are building chat into the browser, what about bringing the browser into our chat-based agents? We had Paul Klein, the founder of Browserbase, join us to talk about this exact topic. His company is tackling one of the biggest hurdles for AI agents: authentication.
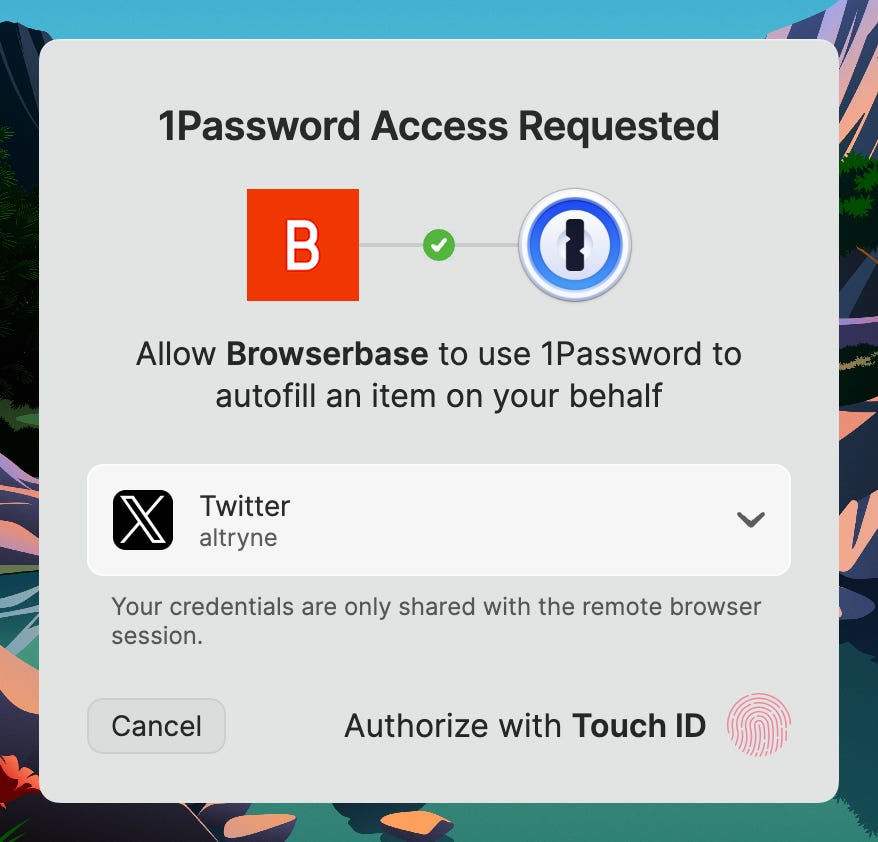
Paul and his team launched Director 2.0, a platform that lets you build web automation with natural language prompts. But the real innovation here is their integration with 1Password. Instead of giving an agent the “master keys” to all your logged-in sessions like Atlas does, Browserbase allows for delegated, per-site authentication. When an agent running in the cloud needs to log into a site on your behalf, you get a prompt on your local machine to approve it. This is a much safer, more granular way to give agents the access they need. As Paul said, you shouldn’t let an AI the master keys into your house; you should give it permission to enter one room at a time. It’s a brilliant paradigm for secure agentic workflows and I really like this approach of a piece-meal authentication for browser agents. I wish Atlas has something like this for the incognito mode!
Director 2.0 itself is like V0 for web automation—you give it a prompt, it performs the task, and then it gives you a repeatable script you can deploy. It’s a way to create robust automations without needing to be a developer, and it’s already being used to automate thousands of hours of manual work.
Video & Audio: The Race to Real-Time
The world of generative media is moving at lightning speed, with a clear trajectory towards real-time, interactive experiences.
Decart’s Real-Time Lip Sync API (X)
We had Kwindla Kramer, one of the worlds leading experts in real-time audio, join us to break down a phenomenal release from Decart AI: a real-time lip-sync API. This isn’t the pre-rendered, slightly-off lip-sync we’re used to. This is a pipeline of models working together to generate perfectly synchronized lip movements for an avatar in real-time.
Kwindla explained the tech stack: it captures your audio via WebRTC, sends it to Whisper for transcription, gets a response from an LLM like Grok, generates a voice with ElevenLabs, and then Decart’s model modifies the avatar’s video frames to match the new audio, all with a sub-two-second latency. This is how we get to truly interactive, believable AI characters. Kwindla even built a quick demo, though it didn’t seem to work the in the morning, probably GPU issues, so we just played the demo videos.
LTX-2 and Sora’s Pet Cameos
The trend towards high-fidelity, real-time generation continued with a breaking news release from Lightricks: LTX-2. This is an open-source (weights coming this fall!) engine that can generate native 4K video with synchronized audio. It’s fast, efficient, and is set to be a powerful open alternative to closed models like Sora. And it’s a native 4K, no upscaling!
Speaking of Sora, they announced that character cameos are getting an upgrade. Soon, you’ll be able to turn anything—your pet, a coffee cup, or even a sunny-side-up egg—into an animated, talking character. I’m really looking forward for this new Sora update and will let you know my impressions when it drops (soon, according to Bill from OpenAI)
What a week folks! What A WEEK! 😅 My head is still spinning!
From browsers that can do our work for us to OCR that redefines context, we’re seeing foundational shifts across the board. The tools are getting more powerful, more accessible, and more integrated into our daily workflows. The future is being built right now, and we get to watch it happen week by week.
Thank you for being a ThursdAI subscriber. As always, here are the show notes with all the links and details from this week’s whirlwind of AI news.
Hosts and Guests
Open Source LLMs
DeepSeek-OCR: Efficient Vision-Text Compression for Massive Contexts (X, HF, Paper)
Liquid AI LFM2-VL-3B: Tiny Multilingual Vision-Language Model (X, HF)
PokeeResearch-7B: Open-source SOTA Deep Research Agent (X, HF, Web, ArXiv, GitHub)
Qwen3-VL 2B & 32B: compact STEM-tuned multimodal powerhouses (X, Hugging Face)
Big CO LLMs + APIs
This weeks Buzz
Fully connected comes to Tokyo (Oct 30-31) and London (Nov 4-5) ! (register at Fullyconnected.com)
Vision & Video
Voice & Audio
Decart Lip Sync API: Real-Time Avatar Lip Movement (X)
Tools
Browserbase launches Director 2.0: prompt-powered web automation (X, Director.ai, Stagehand)